The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
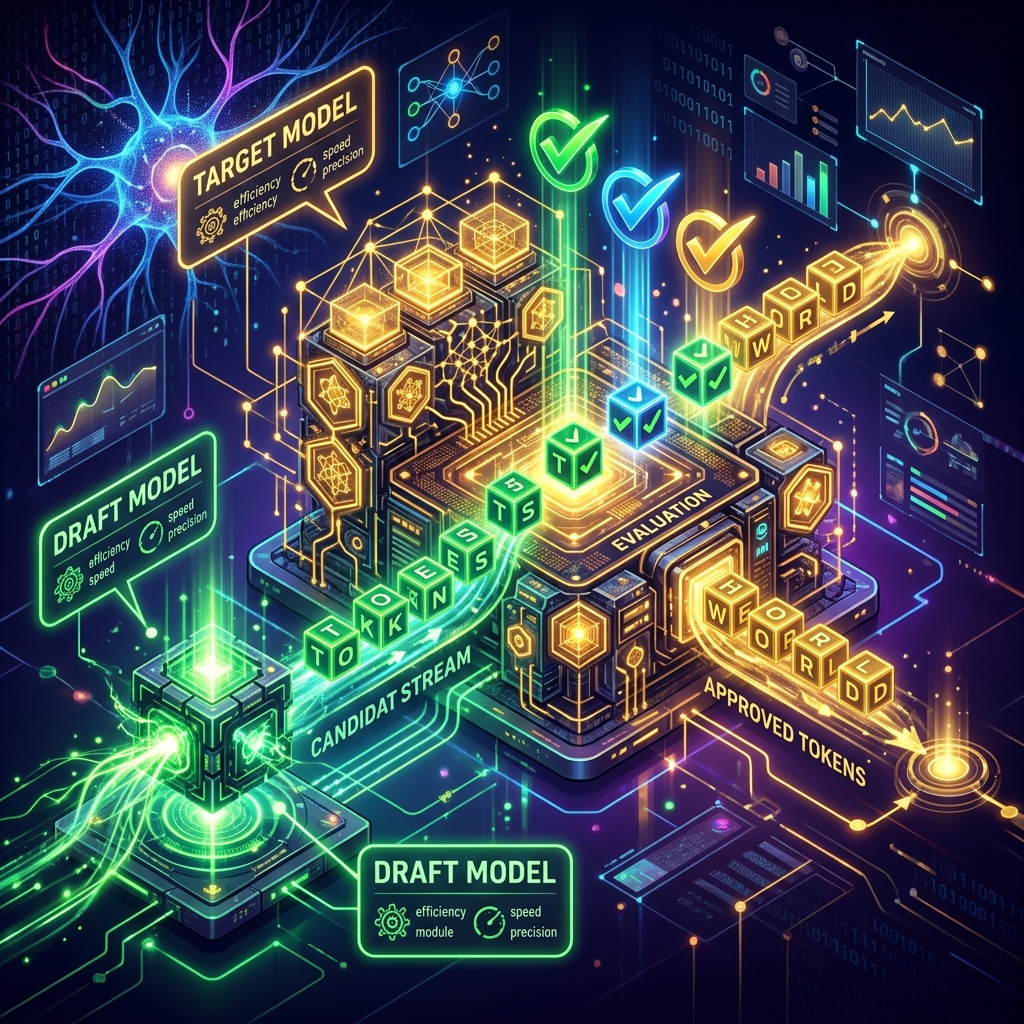
LLM inference is notoriously slow and hardware-intensive due to memory bottlenecks. Speculative decoding solves this by using a lightweight draft model to propose tokens, slashing latency and hosting costs.
Large Language Model inference is notoriously slow and resource-heavy. Because autoregressive models generate text token-by-token sequentially—requiring a full forward pass of the inside-a-100-automated-accounting-department" class="internal-link">automated-her-entire-department--and-kept-her-job" class="internal-link">entire model parameter space for every single character—inference is bounded by memory bandwidth rather than raw compute...
Continue reading →
Mathematicians are rallying behind the Leiden Declaration to defend scientific rigor from neural network hallucinations. Inside the conflict between black-box AI logic and formal verification systems like Lean.

OpenAI's GPT-5.6 Sol and Anthropic's Mythos AI marks a major pivot: the transition from public model APIs to nation-state audited, restricted-access frontier models. Here is the technical comparison.
Autoregressive text generation is slow and expensive. Speculative decoding speeds up inference by running a lightweight 'draft' model alongside your target model. Here is the production-grade architecture and benchmarking code.
The tools got better than the processes. Now the processes have to catch up.— FROM 'THE AUTOMATION PARADOX,' ISSUE NO. 19