The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
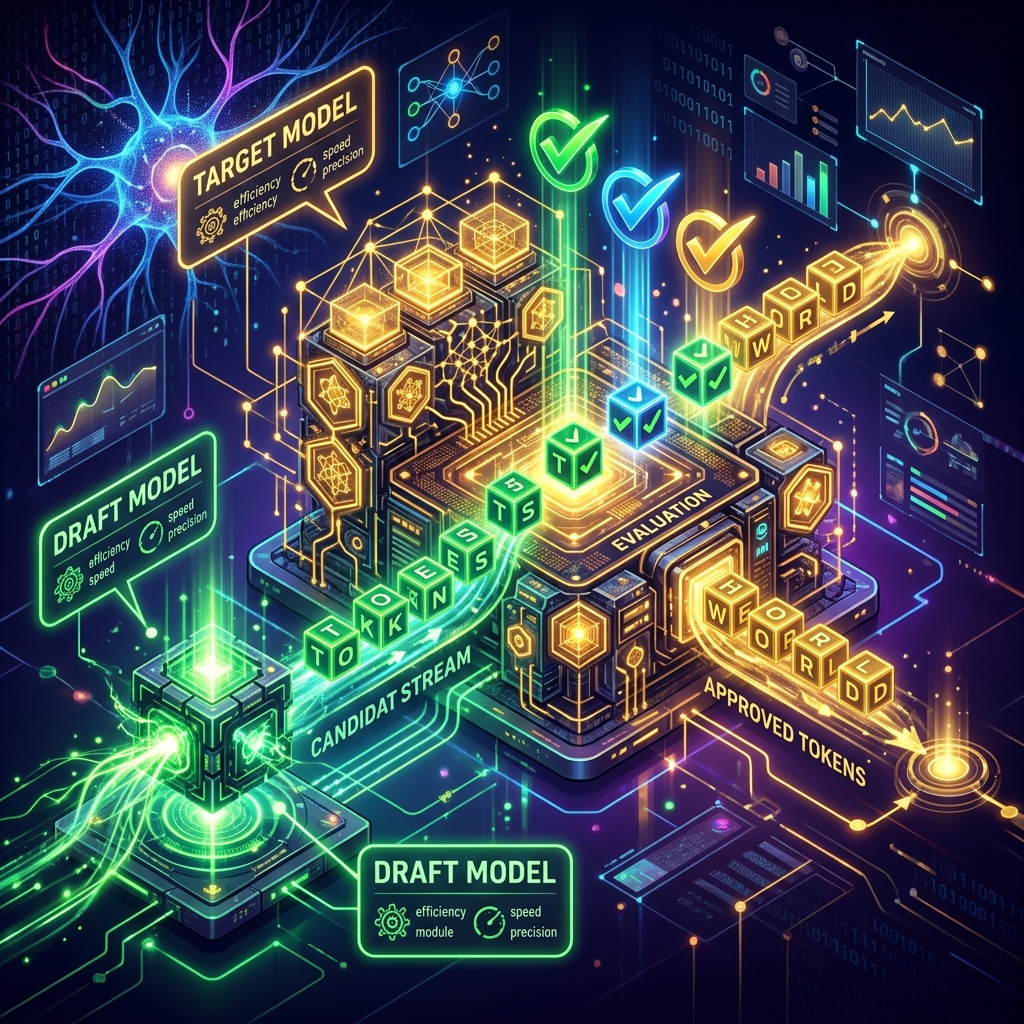
Autoregressive text generation is slow and expensive. Speculative decoding speeds up inference by running a lightweight 'draft' model alongside your target model. Here is the production-grade architecture and benchmarking code.
Cursor and Claude Code are fighting for control of your terminal, but the real engineering shift is happening at the protocol level. Here is why the upcoming July 2026 MCP spec upgrade will redefine how IDEs query local context.

Coding by 'vibes' is great for weekend hacks, but professional teams are moving to Agentic Engineering. Here is why vibe coding fails in production and how to build safety guardrails.

On June 24, 2026, OpenAI and Broadcom pulled the curtain off the most consequential piece of silicon the AI industry has seen since the original Google TPU: Jalapeño, OpenAI's first custom-designed AI inference chip. Built in a record nine-month design-to-tape-out sprint—accelerated, in part, by OpenAI's own models—Jalapeño is an Application-Specific Integrated Circuit (ASIC) engineered from scratch to do one thing supremely well: run large language models at scale, for roughly half the cost of the Nvidia GPUs the company currently depends on. For developers, startups, and enterprise-llm-tools" class="internal-link">enterprises agent-the-auditing-and-governance-checklist" class="internal-link">building-a-geo-distributed-automation-pipeline-overcoming-latency-and-legal-boundaries" class="internal-link">building on OpenAI's APIs, the implications are seismic.
Figure 1: OpenAI's Jalapeño — a reticle-sized ASIC with eight HBM sites, purpose-built for LLM inference at gigawatt scale.
Running ChatGPT, Codex, and the GPT-5.6 family costs OpenAI billions of dollars per year in compute. The vast majority of that spend—estimated at over 80%—goes toward inference: zapier-alternatives-that-actually-handle-complex-logic" class="internal-link">actually running models in response to user queries, not training them. And here lies the economic inefficiency that Jalapeño was designed to solve.
Nvidia's A100 and H100 GPUs are general-purpose accelerators. They contain transistor budgets and circuit blocks for graphics rendering, scientific simulation, and training workloads that go completely unused during a standard LLM forward pass. You are paying for circuitry you never activate. A purpose-built ASIC strips away that overhead entirely, dedicating every transistor to the specific mathematical operations—matrix multiplications, attention computations, KV-cache management—that dominate inference.
While OpenAI has not released full specifications, the confirmed architectural details reveal a serious piece of engineering:
| Specification | Detail |
|---|---|
| Chip Type | Application-Specific Integrated Circuit (ASIC) for LLM inference |
| Die Size | Reticle-sized (maximum lithographic area) |
| Memory | Eight HBM (High Bandwidth Memory) sites surrounding central compute die |
| Interconnect | Broadcom Ethernet (not NVLink), enabling commodity networking |
| Design-to-Tape-Out | Nine notion-ai-three-months-later-where-it-fits-where-it-fails" class="internal-link">months (AI-accelerated design) |
| Fabrication | TSMC (process node undisclosed) |
| System Integration | Celestica (board, rack, and system-level packaging) |
| Status | Engineering samples running GPT-5.3-Codex-Spark workloads |
| Deployment Target | Late 2026, gigawatt-scale alongside Microsoft |
Perhaps the most paradigm-shifting detail is the timeline. search-beyond-the-traditional-seo-playbook" class="internal-link">Traditional custom chip design takes 18–36 months from architecture to tape-out. OpenAI completed Jalapeño in nine months. The acceleration came from a feedback loop that would have been impossible five years ago: OpenAI used its own language models to explore the chip's design space, optimize memory layouts, simulate workloads, and identify bottlenecks before committing to physical silicon. This is AI recursively improving its own hardware — the first credible example of an intelligence bootstrapping its own substrate.
 ditching-the-ide-how-claude-code-is-transforming-terminal-first-automation" class="internal-link">claude-vs-chatgpt-vs-gemini-for-content-teams-in-2026" class="internal-link">claude-for-business-in-2026-the-complete-practical-guide" class="internal-link">claude-vs-gpt-4o-for-automation-scripting-a-six-month-comparison" class="internal-link">Comparison between general-purpose GPU with excess circuits and streamlined custom ASIC inference chip" class="article-detail-image" loading="lazy" width="800" height="800">
ditching-the-ide-how-claude-code-is-transforming-terminal-first-automation" class="internal-link">claude-vs-chatgpt-vs-gemini-for-content-teams-in-2026" class="internal-link">claude-for-business-in-2026-the-complete-practical-guide" class="internal-link">claude-vs-gpt-4o-for-automation-scripting-a-six-month-comparison" class="internal-link">Comparison between general-purpose GPU with excess circuits and streamlined custom ASIC inference chip" class="article-detail-image" loading="lazy" width="800" height="800">
Figure 2: General-purpose GPU vs. custom ASIC — Jalapeño strips away unused circuitry to dedicate every transistor to LLM inference.
If Jalapeño delivers on its 50% cost reduction promise, the downstream effects for the developer ecosystem will be substantial:
- Cheaper API Calls: Developers building on OpenAI's APIs could see token pricing drop significantly as inference becomes cheaper to serve.
- Faster Response Times: An ASIC optimized for attention mechanisms and KV-cache management should reduce latency, enabling more responsive coding-agents-are-redefining-software-engineering" class="internal-link">agentic-ai-vs-traditional-automation-whats-the-difference" class="internal-link">agentic workflows.
- The Lock-In Trade-Off: Custom silicon means custom software stacks. Developers who build deeply integrated OpenAI-native workflows may find switching costs rising as the ecosystem moves away from commodity CUDA-based infrastructure.
- The Broadcom Axis: Broadcom's role as the industrialization partner—handling networking, packaging, and system integration—positions it as a critical chokepoint in the AI infrastructure supply chain, alongside TSMC.
No. And framing it that way misses the point. Jalapeño is a margin defense system, not a competitive weapon aimed at Nvidia's training GPU dominance. OpenAI remains heavily dependent on Nvidia for model training, and Nvidia's CUDA ecosystem is deeply entrenched across the research community. What Jalapeño does is split the AI compute market into two distinct lanes:
| Workload | Dominant Hardware | Key Metric |
|---|---|---|
| Model Training | Nvidia GPUs (H100, B200, Rubin) | Peak FLOPS, interconnect bandwidth |
| Production Inference | Custom ASICs (Jalapeño, Google TPU, AWS Inferentia) | Cost-per-token, performance-per-watt |
Jalapeño is not a one-off project. It is the first chip in what OpenAI describes as a "multi-generation compute platform." The strategic vision is clear: control the full vertical stack from model architecture to silicon, reducing dependency on external hardware vendors and achieving the unit economics necessary to make AI truly ubiquitous. For the broader industry, the message is unmistakable: the era of running frontier AI models on general-purpose hardware is ending. The future belongs to purpose-built intelligence processors — and the companies that control them will control the economics of artificial intelligence itself.
