The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
Large Language Model inference is notoriously slow and resource-heavy. Because autoregressive models generate text token-by-token sequentially—requiring a full forward pass of the inside-a-100-automated-accounting-department" class="internal-link">automated-her-entire-department--and-kept-her-job" class="internal-link">entire model parameter space for every single character—inference is bounded by memory bandwidth rather than raw compute. However, a major optimization framework is gaining rapid adoption across production AI infrastructures: Speculative Decoding. By pairing a massive "target" model with a lightweight, high-speed "draft" model, speculative decoding cuts agent-the-auditing-and-governance-checklist" class="internal-link">building-a-geo-distributed-automation-pipeline-overcoming-latency-and-legal-boundaries" class="internal-link">latency and compute costs by up to 60% without changing the quality of the output. Here is how this mathematical optimization works and why it is transforming enterprise-llm-tools" class="internal-link">enterprise LLM serving.
Figure 1: Speculative Decoding — A lightweight draft model speed-proposes a sequence of tokens, which the heavy target model validates in parallel.
When you run a 70-billion parameter model, every single token generation requires loading all 70 billion weights from High Bandwidth Memory (HBM) to the GPU's registers. This memory transfer takes orders of magnitude longer than the actual mathematical matrix multiplication on the tensor cores. The GPU spend most of its cycles sitting idle, waiting for data to arrive from memory. This is called a **memory-bound** workload.
Speculative decoding solves this by changing the computational math. Instead of loading the massive model weights for every single token, we load a tiny 1-billion parameter "draft" model to predict several tokens ahead in sequence. Because the draft model is tiny, it runs extremely fast. Once a sequence of tokens is proposed, we load the massive "target" model once to evaluate the entire sequence in a single parallel step. This changes the workload from memory-bound to compute-bound, utilizing the GPU's tensor cores to their full potential.
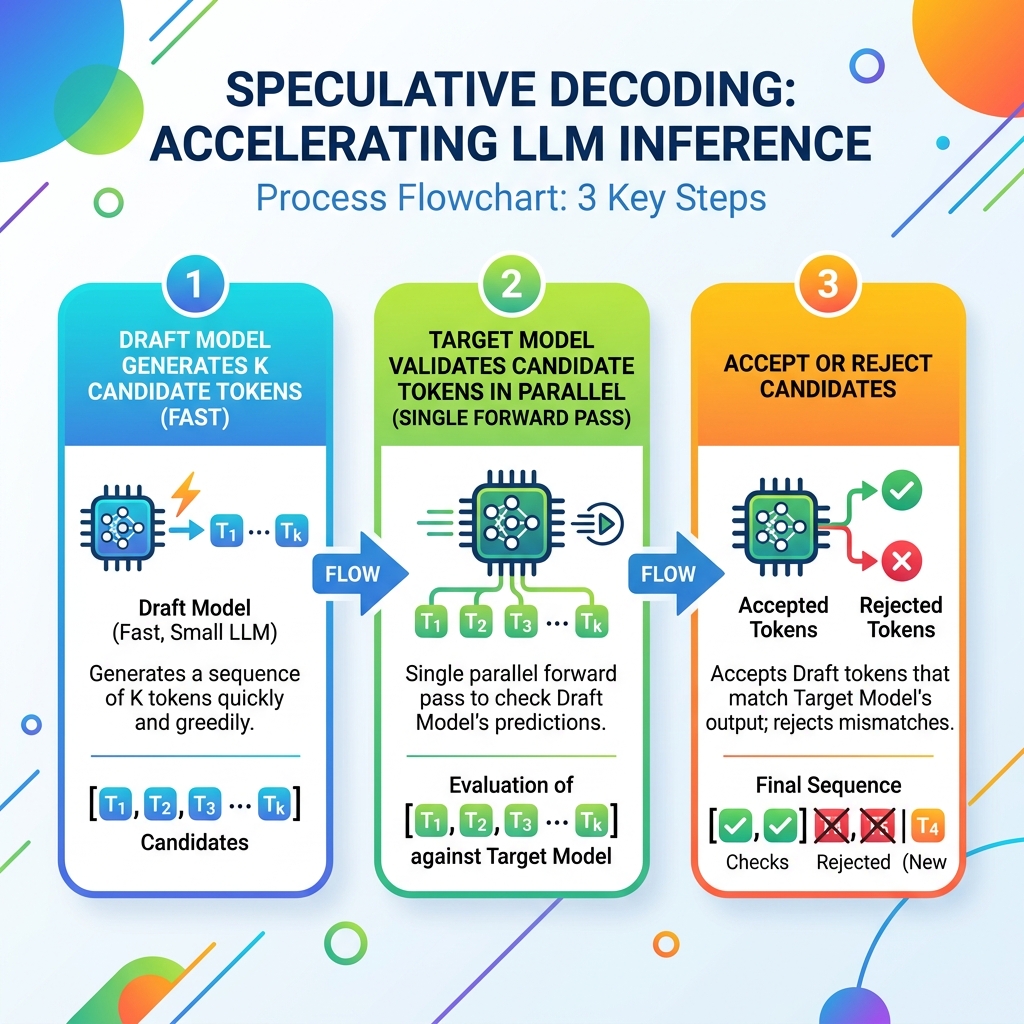
Figure 2: Sequential generation vs. Speculative Decoding — verifying multiple tokens in parallel reduces total memory load operations.
The core genius of speculative decoding lies in the verification step. The target model evaluates the draft model's tokens using a probability check (typically Jacobi iteration or stochastic acceptance rules). If the target model's probability distribution agrees with the draft model's selection, the tokens are accepted. The moment a token notion-ai-three-months-later-where-it-fits-where-it-fails" class="internal-link">fails the probability check, that token and all subsequent tokens in the draft batch are discarded, and the draft model restarts generation from the target model's corrected branch.
Because multiple tokens are verified in a single forward pass, the total number of expensive memory-load operations is slashed. For average hijacks-your-ai-coding-agents-are-redefining-software-engineering" class="internal-link">coding-agent" class="internal-link">coding or prose tasks, the draft model achieves an acceptance rate of 70-80%, yielding a 2x to 3x speedup in token generation speed.
| Metric | Autoregressive Serving | Speculative Serving |
|---|---|---|
| Generation Model | Single target model (e.g. 70B) | Draft model (1B) + Target model (70B) |
| GPU Workload Profile | Memory-bandwidth bound (tensor cores idle) | Compute bound (tensor cores fully utilized) |
| Latency (Time to First Token) | High (linear with sequence length) | Low (slashed by up to 60%) |
| Hardware Efficiency | Poor (expensive GPUs sit waiting for HBM weights) | High (weights loaded once for batch verification) |
| Output Quality | Base (reference target model output) | Identical (target model guarantees math output equivalence) |
For developer and operations teams serving high-volume AI features, speculative decoding can be deployed via local-first-productivity-stack-keeping-workflows-functional-offline" class="internal-link">local-first-workflow" class="internal-link">modern inference engines like vLLM, TensorRT-LLM, or DeepSpeed. Below is a conceptual vLLM configuration showing how to initialize speculative serving using a Llama-3-70B model as the target and a Llama-3-8B model as the draft accelerator:
# Run vLLM speculative server from shell
python -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-70B-Instruct --speculative-model meta-llama/Meta-Llama-3-8B-Instruct --num-speculative-tokens 5 --port 8000In this setup, the server proposes 5 tokens at a time using the 8B draft model and verifies them in parallel using the 70B target model, delivering significant latency improvements for connected API users.
Speculative decoding represents a major architectural milestone in LLM serving. By shifting the workload profile from memory-bound to compute-bound, infrastructure teams can extract higher performance out of existing GPU clusters, lowering operational expenses and improving user experience. As specialized draft models become standard, speculative serving will remain the key optimization layer for production AI pipelines.

