The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
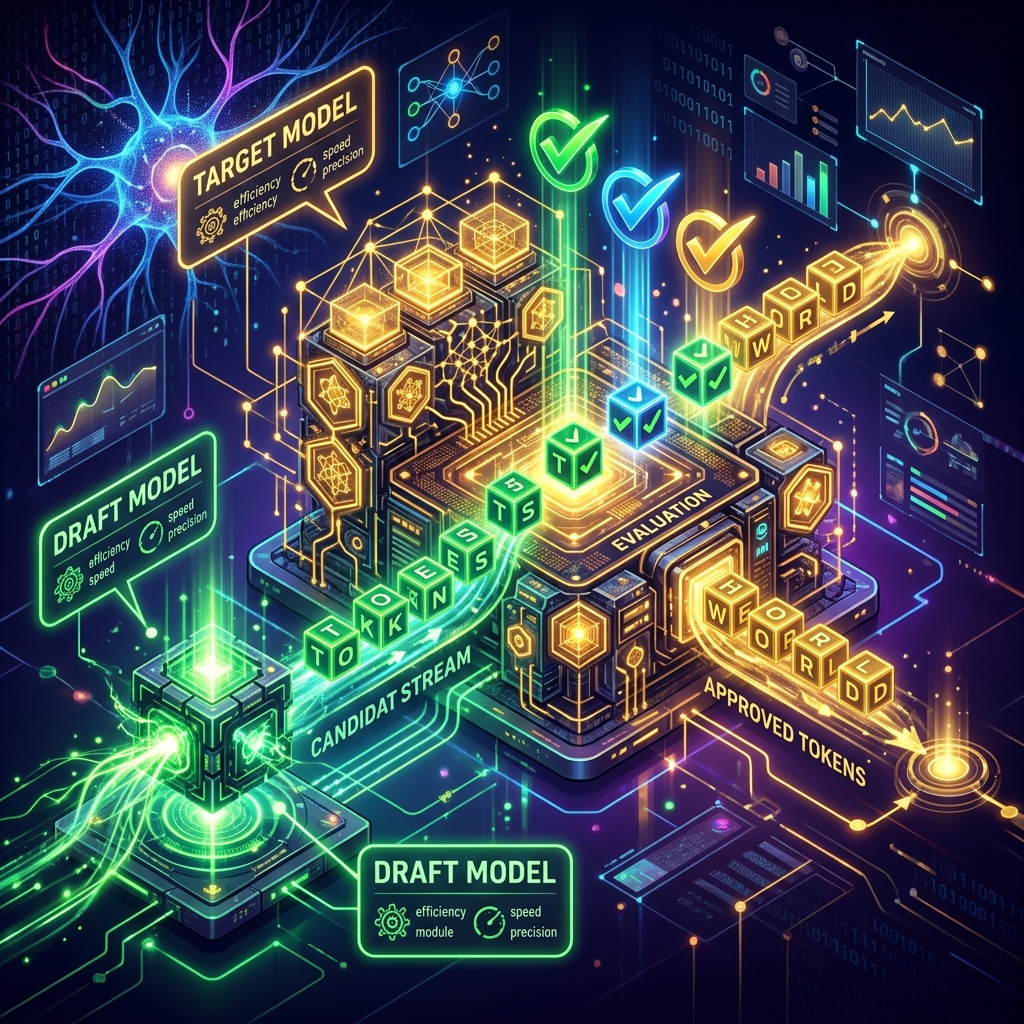
Autoregressive text generation is slow and expensive. Speculative decoding speeds up inference by running a lightweight 'draft' model alongside your target model. Here is the production-grade architecture and benchmarking code.
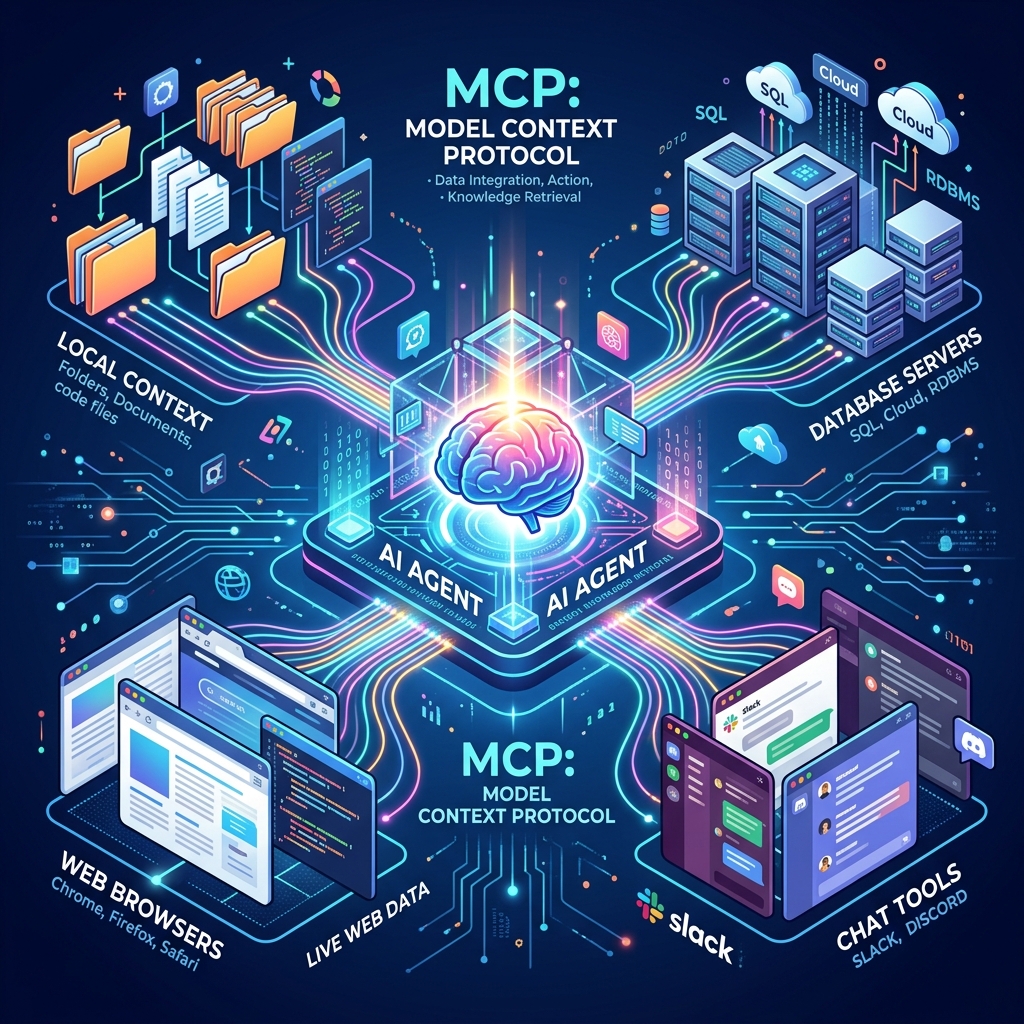
Cursor and Claude Code are fighting for control of your terminal, but the real engineering shift is happening at the protocol level. Here is why the upcoming July 2026 MCP spec upgrade will redefine how IDEs query local context.

Coding by 'vibes' is great for weekend hacks, but professional teams are moving to Agentic Engineering. Here is why vibe coding fails in production and how to build safety guardrails.

On June 26, 2026, OpenAI introduced the most significant model release in its history — and then immediately told the public they couldn't use it. The GPT-5.6 family, consisting of notion-ai-three-months-later-where-it-fits-where-it-fails" class="internal-link">three distinct tiers named Sol (flagship), Terra (balanced), and Luna (fast), represents a generational leap in reasoning, coding, and scientific capability. But in a first for the commercial AI industry, the U.S. government has intervened in the release process, restricting access to roughly 20 individually vetted organizations while safety assessments continue. This article breaks down what the models can do, why the government stepped in, and what it all means for the developer ecosystem.
Figure 1: The GPT-5.6 trinity — Sol (flagship reasoning), Terra (balanced daily driver), and Luna (fast, cost-efficient automation).
OpenAI has abandoned the confusing naming conventions of the past. The "5.6" designates the generation; the celestial names designate the capability tier. Here is what each model is designed for:
| Model | Tier | Best For | Key Features | Cost vs. GPT-5.5 |
|---|---|---|---|---|
| Sol | Flagship | Complex reasoning, frontier coding, scientific research, cybersecurity analysis | "Max Reasoning Effort" mode, "Ultra Mode" with specialized sub-agents, state-of-the-art on Terminal-Bench 2.1 | Premium tier |
| Terra | Balanced | enterprise-llm-tools" class="internal-link">Enterprise workflows, everyday coding, claude-vs-chatgpt-vs-gemini" class="internal-link">content generation, ditching-the-ide-how-claude-code-is-transforming-terminal-first-automation" class="internal-link">claude-vs-chatgpt-vs-gemini-for-content-teams-in-2026" class="internal-link">claude-for-business-in-2026-the-complete-practical-guide" class="internal-link">business automation | GPT-5.5-level performance at ~2x lower cost, ideal for production workloads | ~50% cheaper |
| Luna | Fast | High-volume automation, summarization, drafting, latency-sensitive applications | Fastest model in the family, lowest cost-per-token, optimized for throughput | Significantly cheaper |
The three-tier structure is a direct acknowledgment that not every task needs frontier intelligence. A customer support chatbot doesn't need Sol's deep reasoning engine; Luna handles it faster and cheaper. A developer debugging a production outage at 3 AM does need Sol's "Ultra Mode," which deploys specialized sub-agents to decompose and attack complex problems from multiple angles simultaneously.
Sol has set new state-of-the-art records on multiple benchmarks that matter to working developers and researchers:
- Terminal-Bench 2.1: The gold standard for evaluating agentic-ai-vs-traditional-automation-whats-the-difference" class="internal-link">agentic coding capability — the ability to navigate a real terminal, read codebases, write implementations, run tests, and debug failures. Sol achieves the highest score ever recorded.
- GeneBench v1: A benchmark for biological and chemical reasoning. Sol demonstrates significant improvements, which is also the source of the government's safety concerns.
- Cybersecurity Evaluations: Sol scored 96.7% on OpenAI's internal cyberattack benchmarks, crossing the "High" risk threshold under the company's Preparedness Framework. This single metric is arguably the reason the government intervened.

Figure 2: The unprecedented gatekeeping — U.S. government vetting determines which organizations gain access to GPT-5.6 Sol.
The restricted release of GPT-5.6 is unprecedented in commercial AI. Here is what triggered it:
On June 2, 2026, the White House issued an Executive Order establishing new oversight mechanisms for frontier AI models that cross defined capability thresholds. This followed warnings from the Five Eyes intelligence alliance (U.S., U.K., Canada, Australia, New Zealand) about the potential for frontier AI to accelerate offensive cyber operations — specifically, the ability to autonomously discover zero-day vulnerabilities, generate novel malware, and orchestrate multi-stage attacks against critical infrastructure.
Sol's 96.7% score on OpenAI's internal cyberattack benchmarks put it squarely above the threshold. The result: the U.S. government requested that OpenAI limit the initial release to a small group of approximately 20 "trusted partners," each individually vetted and approved by government officials. Access is currently available only through the API and Codex developer tools — not through ChatGPT or any public-facing consumer product.
| Capability | Risk Category | Government Concern |
|---|---|---|
| Autonomous vulnerability discovery | Cyber Offense | Model could identify zero-day exploits faster than human red teams |
| Malware generation | Cyber Offense | Model could generate novel, undetectable malicious code |
| Chemical/biological reasoning | CBRN | Model could assist in designing harmful compounds |
| Multi-step attack orchestration | Cyber Offense | Model could plan and execute coordinated infrastructure attacks |
| Social engineering at scale | Information Operations | Model could generate hyper-personalized phishing at mass scale |
If you are a developer or enterprise team building-a-geo-distributed-automation-pipeline-overcoming-latency-and-legal-boundaries" class="internal-link">building on OpenAI's ecosystem, here is the practical guidance:
- If you have access: Coordinate with your OpenAI account representative. API access does not automatically include Codex, and vice versa. Test Sol's "Ultra Mode" for your most complex agentic workflows — the sub-agent decomposition is genuinely novel.
- If you don't have access: There is no public waitlist. Prepare your codebase for migration by reviewing your current model version pinning. The general release is expected in mid-July 2026.
- Evaluate Terra immediately: For most production workloads, Terra at 50% of GPT-5.5's cost is the real story. Audit your current API usage and identify workloads that can be downgraded from Sol-class to Terra-class without quality loss.
- Build with Luna for scale: If you run high-volume automation, summarization pipelines, or customer-facing chatbots, Luna's cost-per-token and latency profile will likely deliver the best ROI.
GPT-5.6 represents a turning point in the relationship between AI companies and governments. The era of "build fast, release publicly, apologize later" is over. The new paradigm is one of negotiated deployment: companies build, governments evaluate, and release schedules are determined by national security calculations rather than product roadmaps. Whether this makes the world safer or simply consolidates power among a small number of pre-approved organizations is the defining question of this era in artificial intelligence. The answer will shape the developer ecosystem — and the broader economy — for years to come.