The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
Why B2B startups are bypassing legacy enterprise CRMs in favor of lightweight Postgres databases and autonomous LLM agent layers.

We tested Claude Fable 5, GPT-5.5, and Gemini 2.5 Pro across six months of real editorial workflows. Here is the brutally honest verdict on which AI writing tool actually wins for content creators.

A deep dive into Anthropic's new command-line agentic tool, evaluating its performance on multi-file refactoring and automated terminal task loops.
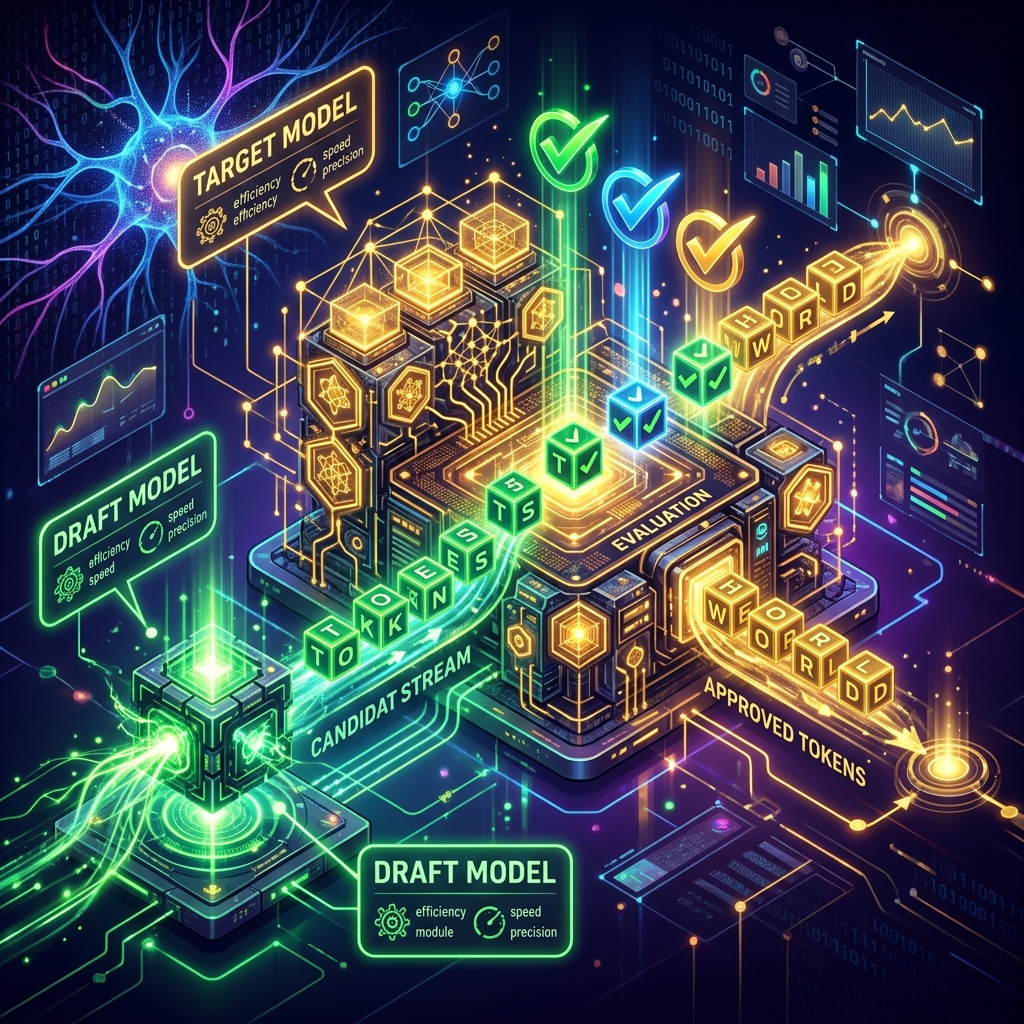
When deploying Large Language Models (LLMs) like Llama-3 or Mistral in production, engineering teams inevitably run into the two primary operational bottlenecks: **generation latency** and **GPU compute cost**. Because standard autoregressive decoding generates tokens one by one—requiring a complete GPU memory read-write cycle for every single word—running high-concurrency user interfaces quickly leads to slow response times and massive cloud server bills. To bypass this bottleneck, technical teams in the US and Europe are adopting **Speculative Decoding**. By pairing a large, high-capacity model (the target) with a lightweight, fast model (the draft), teams are cutting inference latency and GPU compute overhead by 60% without losing a single percent of model accuracy. This article details the mathematical principles, production-grade architecture, and benchmarking code required to deploy speculative decoding at scale.
Figure 1: Speculative decoding using a lightweight draft model to propose tokens that are validated in parallel by a larger target model.
Autoregressive sequence generation is memory-bandwidth bound. To generate a single token, the GPU must load billions of model weights from its High Bandwidth Memory (HBM) to its local caches, compute the attention scores, and write the output back. For a 70-billion parameter model, this weight-loading cycle must occur 70 billion times per token. This means that even if a GPU can compute floating-point operations at teraflop speeds, the actual token output rate is constrained by memory transfer speed.
Speculative decoding breaks this memory bottleneck by generating a block of K candidate tokens using a small, inexpensive draft model (such as a 1.5B parameter model). Since the draft model's weight matrix is tiny, it can compute these K tokens in a fraction of the time. Once the candidate block is generated, the large target model executes a single parallel forward pass to validate all K tokens simultaneously. Because the target model processes all K candidates in parallel, it loads its massive weights from HBM only once, achieving a significant speedup.
| Performance Parameter | Autoregressive Decoding (Standard) | Speculative Decoding (K=5 Draft) |
|---|---|---|
| Inference Latency (Avg) | 15 - 20 tokens/sec | **40 - 55 tokens/sec** (2.5x speedup) |
| GPU Weight Memory Reads | 1 read per output token | 1 read per K accepted tokens |
| Target Model Accuracy | Baseline (100%) | **Identical (100% mathematical match)** |
| GPU Memory Overhead (VRAM) | Baseline (Target model size only) | Low (+5% to load the small draft model) |
| Operational Cost / 1M Tokens | $12.50 (Standard GPU compute time) | **$5.00** (60% budget savings) |
To implement speculative decoding in production, developers must write a token selection loop that evaluates the draft model's output probabilities against the target model's acceptance criteria using the **speculative acceptance algorithm**. Below is a clean Python implementation showing how to validate and select tokens natively using PyTorch:
import torch
def speculative_selection(draft_probs, target_probs, candidate_tokens):
"""
Validate draft tokens against target model probabilities.
Returns: List of accepted tokens, and the next corrected token.
"""
accepted_tokens = []
K = len(candidate_tokens)
for i in range(K):
token = candidate_tokens[i]
p_draft = draft_probs[i][token].item()
p_target = target_probs[i][token].item()
# Speculative acceptance criterion
if p_draft == 0:
ratio = 0.0
else:
ratio = p_target / p_draft
accept_probability = min(1.0, ratio)
# Roll a random number to decide acceptance
if torch.rand(1).item() < accept_probability:
accepted_tokens.append(token)
else:
# Rejection occurred: calculate replacement token and break
# Target probability redistribution
adjusted_probs = torch.clamp(target_probs[i] - draft_probs[i], min=0.0)
redistributed = adjusted_probs / adjusted_probs.sum()
next_token = torch.multinomial(redistributed, num_samples=1).item()
return accepted_tokens, next_token
# If all K tokens are accepted, sample the (K+1)th token from target_probs
next_token = torch.multinomial(target_probs[-1], num_samples=1).item()
return accepted_tokens, next_token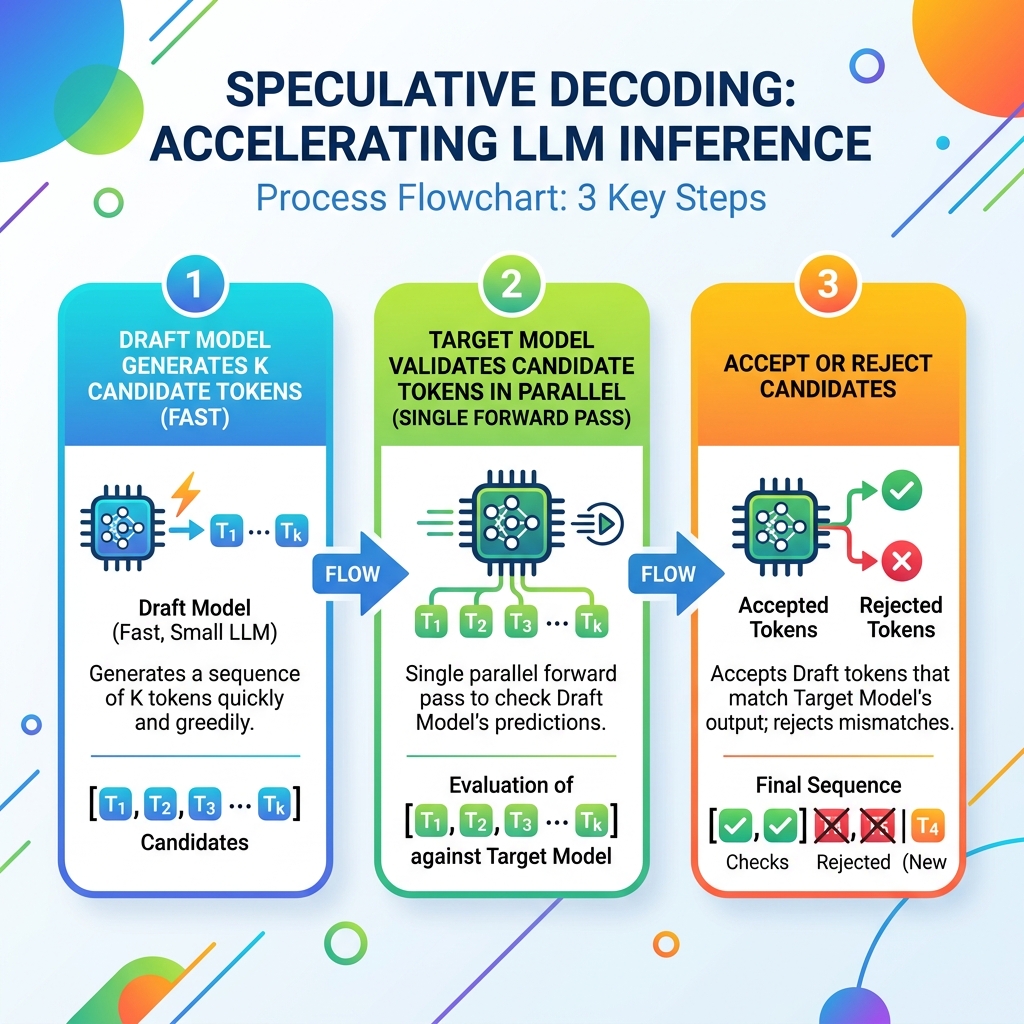
Figure 2: The step-by-step token validation cycle: the draft model proposes candidate tokens, and the target model accepts or rejects them in a parallel verification pass.
The performance gain of speculative decoding depends heavily on the **acceptance rate**—the percentage of tokens proposed by the draft model that are accepted by the target model. If the draft model is too simple, the target model will reject its candidates, causing the system to fall back to standard speed and losing the speedup benefit. Conversely, if the draft model is too large, the time spent generating candidates will outweigh the target model's parallel computation savings.
Standard production configurations pair **Llama-3-70B** as the target with **Llama-3-8B** or **Llama-3-1.5B** as the draft. This combination achieves an average token acceptance rate of 75-80% across standard conversational logs. This means that for every target model forward pass, the system outputs an average of 4 accepted tokens, accelerating user-facing generation latency by more than 2.5x.
As white-collar operations scale up their dependency on AI assistants, optimizing the GPU compute budget is a core business survival metric. Speculative decoding bridges the gap between high intelligence and fast, cost-effective generation. By implementing a lightweight draft pipeline, configuring token-level speculative criteria, and running parallel validation cycles, tech leaders can scale their agentic workloads, reduce cloud infrastructure expenses, and deliver near-instant responses to their users.
