The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

Coding by 'vibes' is great for weekend hacks, but professional teams are moving to Agentic Engineering. Here is why vibe coding fails in production and how to build safety guardrails.

How to self-host Cohere-v3 or BGE-M3 models locally, achieving sub-5ms vectorization latency while preserving privacy.
Why B2B startups are bypassing legacy enterprise CRMs in favor of lightweight Postgres databases and autonomous LLM agent layers.

When autonomous coding agents first hit the developer scene, the promise was total autonomy. Startups advertised agents that could read an entire repository, write hundreds of lines of code, commit the modifications, and push directly to staging without human oversight. However, as senior software teams deployed these systems in high-scale production environments, they hit a hard wall of reliability. Agents got caught in infinite loops, introduced undetected memory leaks, and overwrote critical zapier-alternatives-that-actually-handle-complex-logic" class="internal-link">logic. The developer community is realizing that treating LLMs as independent autonomous actors is an architectural anti-pattern. Instead, the industry is shifting toward **Harness Engineering**—the practice of building-a-geo-distributed-automation-pipeline-overcoming-latency-and-legal-boundaries" class="internal-link">building strict, deterministic "outer loops" (type checkers, testing containers, and static compilation gates) that surround, validate, and constrain LLM outputs.
Figure 1: Harness Engineering: Wrapping the raw generative model core with deterministic compile, test, and security rings.
Why do raw agents fail? An LLM is, at its core, a probabilistic token predictor. It does not possess a compiler, a memory space, or a conceptual model of execution. When an agent is given direct write access to a filesystem, it behaves like an unaudited junior developer. It writes code that *looks* syntactically correct, but may fail during execution due to runtime errors, missing imports, or security vulnerabilities. The risks of unchecked agentic execution fall into notion-ai-three-months-later-where-it-fits-where-it-fails" class="internal-link">three categories:
- **Runaway Writes**: An agent attempting to debug a compile error might continuously rewrite files, eventually corrupting the codebase or causing runaway disk utilization.
- **The Hallucinated Dependency Trap**: Agents often import third-party packages that do not exist, exposing the system to dependency confusion attacks or compiler failures.
- **State Drift**: Because agents run asynchronously, they can read file state at time T1, make changes, and write at T2, overriding concurrent changes and causing state drift.
| Dimension | Raw Agent Autonomy | Harness Loop Architecture |
|---|---|---|
| Write Target | Directly to the active codebase filesystem | An isolated sandbox jail directory |
| Validation Phase | None, or left to post-commit CI/CD runs | Pre-write compilation, linting, and unit testing |
| Execution Safety | High-risk; agent can overwrite active processes | Zero-risk; runs inside secure sandboxed Docker jails |
| Control Mechanism | System prompt-engineer-is-a-transitionary-role" class="internal-link">prompts and raw LLM decision gates | Deterministic loop scripts (Python, Node) wrapping LLM calls |
| Reliability Rate | Low (frequent compile and runtime breaks) | High (only code that compiles and passes tests is saved) |
Harness Engineering shifts the focus from writing the perfect system prompt to designing the perfect validation pipeline. A modern software harness wraps the LLM query in a multi-stage validation loop. Below is a conceptual implementation of a Python verification harness. It takes an agent's code proposal, writes it to a temporary sandbox directory, compiles it, and executes unit tests. If the compilation or tests fail, the harness feeds the exact error logs *back* to the LLM, forcing it to debug itself until it produces certified, compilable code:
import subprocess
import os
class SoftwareHarness:
def __init__(self, sandbox_dir="sandbox"):
self.sandbox = sandbox_dir
os.makedirs(self.sandbox, exist_ok=True)
def validate_proposal(self, filename, code_content, test_command):
# 1. Write proposed code to isolated sandbox jail
temp_file_path = os.path.join(self.sandbox, filename)
with open(temp_file_path, "w") as f:
f.write(code_content)
# 2. Compile and syntax check
compile_result = subprocess.run(
["python", "-m", "py_compile", temp_file_path],
capture_output=True, text=True
)
if compile_result.returncode != 0:
return False, f"Syntax Error: {compile_result.stderr}"
# 3. Run test suite inside sandbox
test_result = subprocess.run(
test_command, cwd=self.sandbox,
capture_output=True, text=True, shell=True
)
if test_result.returncode != 0:
return False, f"Test Suite Failed: {test_result.stderr}"
return True, "Code successfully compiled and validated."
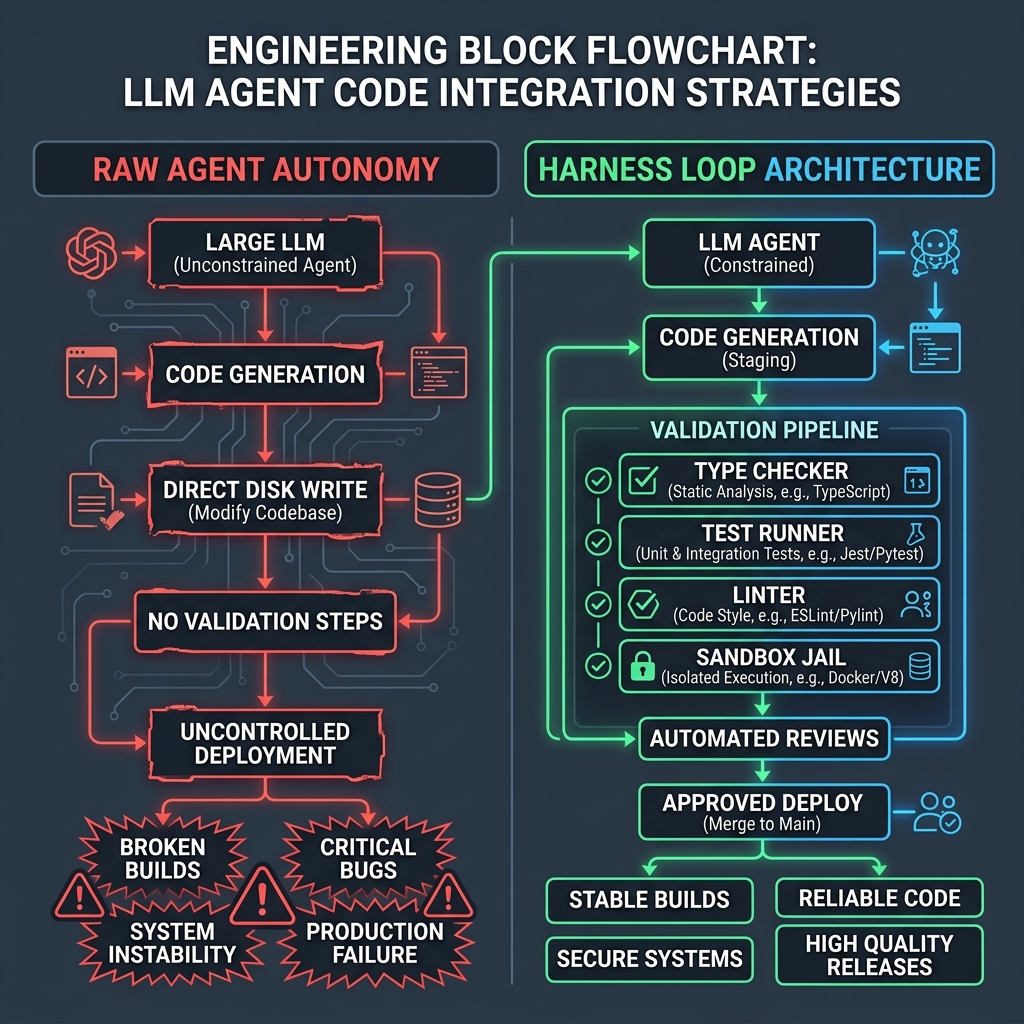
Figure 2: The contrast: raw agentic disk writes vs. the self-correcting Harness Loop pipeline that guarantees compilable commits.
Once a single-agent harness is in place, developers can scale the architecture to multi-agent loops. Instead of asking one model to plan, code, write tests, and deploy, the loop orchestrator coordinates teams of specialized, micro-prompted agents. A dedicated *Product Agent* defines the requirement, a *Coding Agent* writes the implementation in the sandbox, a *QA Agent* drafts test cases, and the *Harness Compiler* runs the loop. The code is only committed to the main branch when every agent's contribution has compiled and passed the testing suite.
The transition from raw agent autonomy to Harness Engineering represents the maturity phase of AI software development. By treating LLMs as probabilistic code generators and wrapping them in deterministic verification harnesses, developers can harness the speed of AI without sacrificing the reliability of search-beyond-the-traditional-seo-playbook" class="internal-link">traditional engineering. Understanding loop orchestration, sandbox compilers, and automated verification is the key to building stable, AI-native software architectures.