The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
For the past four years, AI-assisted development has followed a simple, flat-rate pricing model. For $10 to $20 a month, developers had unlimited autocomplete, inline edits, and chat requests. It was the golden age of cheap compute, heavily subsidized by big-tech cloud infrastructure. But in June 2026, that era came to an end. Microsoft and GitHub's sudden transition to token-based billing for GitHub Copilot Agent Mode sparked widespread backlash, forcing developers to confront a harsh new reality: agentic coding sessions are becoming prohibitively expensive.
The core problem lies in the transition from simple autocomplete (which consumes a few hundred tokens per request) to autonomous agentic workflows. When you ask an AI coding agent to debug a complex repository, search through files, run terminal commands, and self-correct, the context window usage explodes. A single agentic task can easily consume 500,000 to 1,000,000 tokens in a matter of minutes as the agent repeatedly feeds the entire codebase state back into the model.
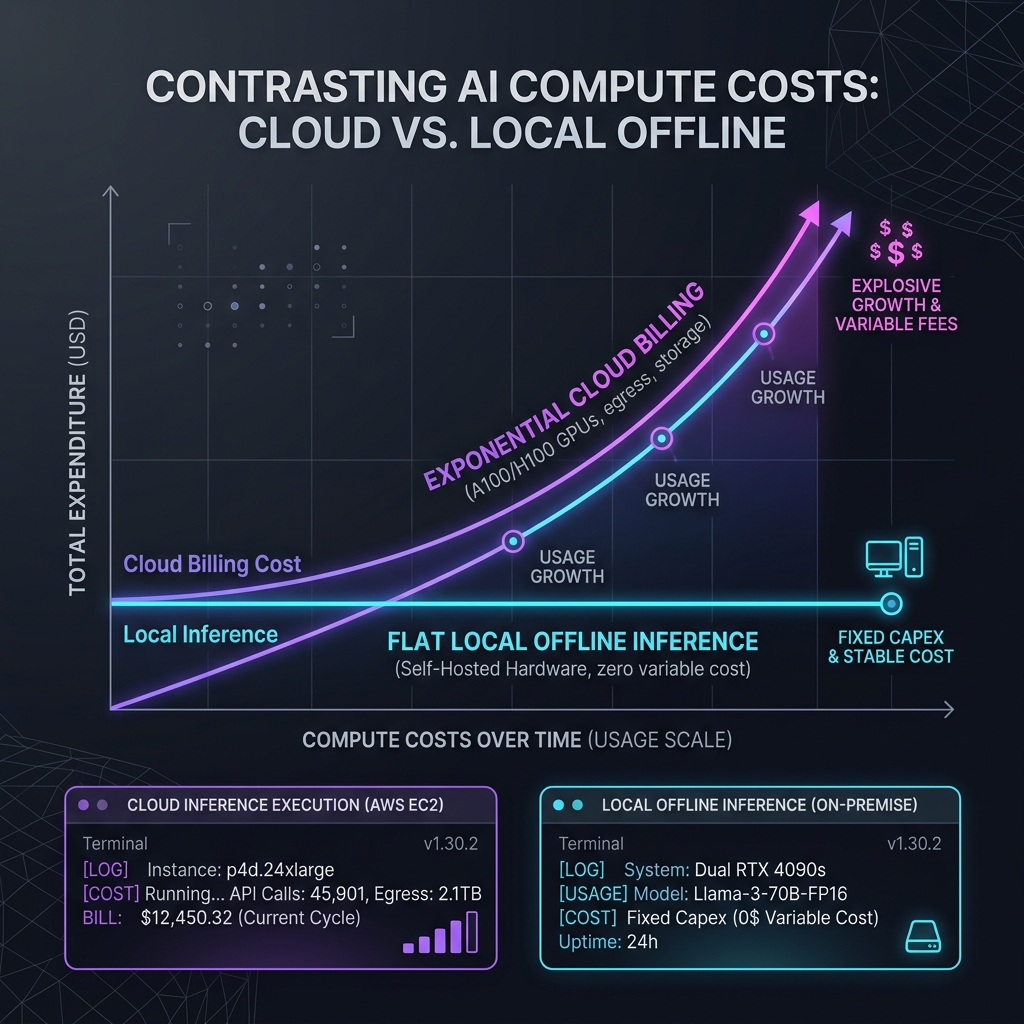
Under a flat-rate model, this usage profile is financially unsustainable for cloud providers. The introduction of token-based pricing was inevitable, but for developers, it represents a massive "Copilot Tax." Long debugging loops that once cost pennies now generate significant API bills, forcing teams to budget their prompts and ration their AI usage.
In response to the Copilot Tax, technical teams are pivoting to a local-first AI architecture. By hosting quantized models directly on developer workstations, teams can completely bypass cloud API limits, network latency, and data privacy concerns. The local-first stack relies on three primary pillars:
As we discussed in our recent breakdown of the Zero-Server AI Stack, the performance of local models is now highly competitive with frontier cloud models for daily coding tasks, delivering near-zero marginal cost per token.
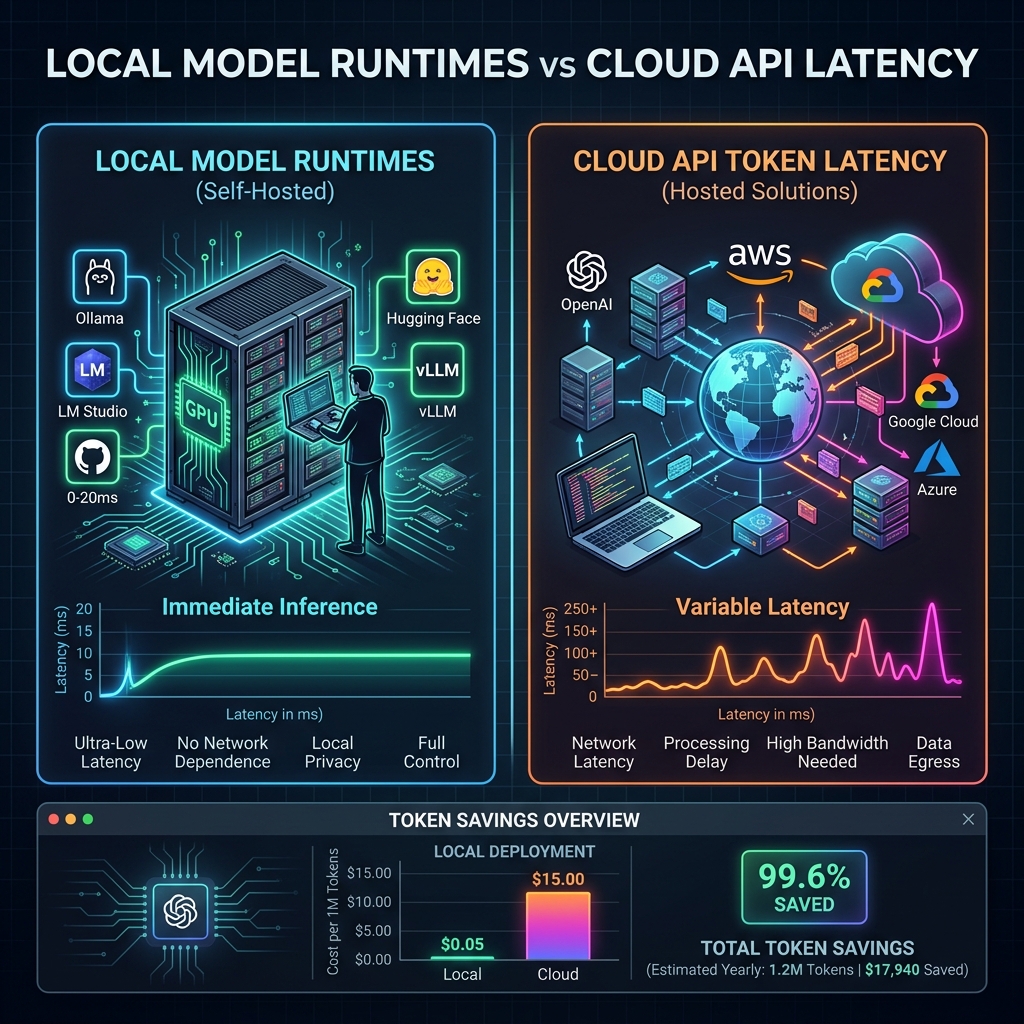
To help you evaluate the trade-offs of migrating away from cloud-hosted AI, we have summarized the key metrics of the leading setups below:
| Feature | GitHub Copilot (Agent Mode) | Cursor + Cloud API Keys | Local Stack (Ollama + Continue) |
|---|---|---|---|
| Cost Basis | Token-Based Billing | Pay-per-use (Pay-as-you-go) | Zero ($0/month after hardware) |
| Token Latency | 150ms - 400ms | 100ms - 300ms | < 50ms (Local cache) |
| Offline Capability | None (Requires internet) | None (Requires internet) | 100% Offline Functional |
| Codebase Privacy | Subject to Cloud Terms | Opt-out telemetry available | Complete local data isolation |
A pure local-first model is highly efficient, but it does have limitations when dealing with ultra-complex, multi-file reasoning that requires frontier models (like Claude 3.5 Sonnet or GPT-5). The ultimate solution for modern developers is a hybrid workflow:
By shifting from flat-rate subscriptions to this hybrid architecture, developers can dodge the Copilot Tax, retain complete control over their codebase security, and build a highly optimized dev stack. The era of blind reliance on cloud AI is over; the future belongs to local control.