The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
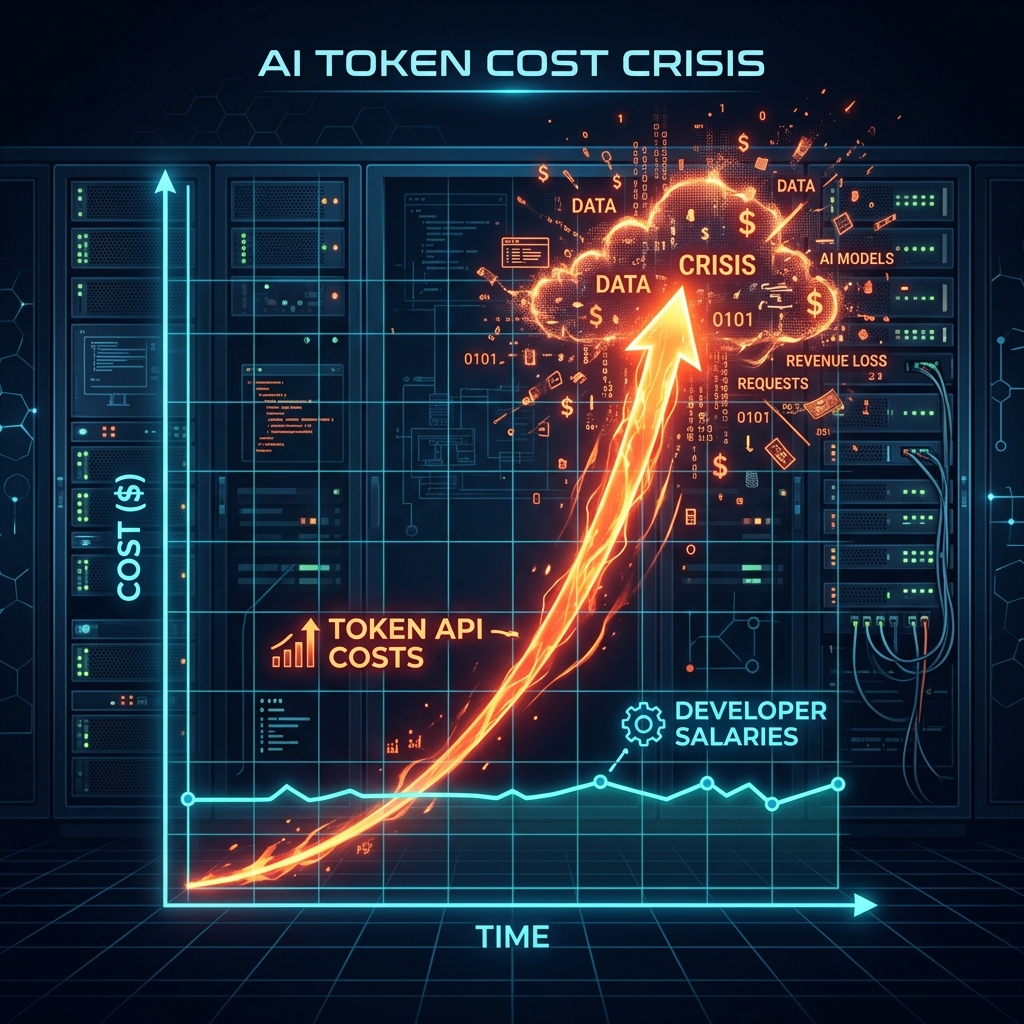
As software engineering organizations move past basic "Copilot" code autocomplete tools and integrate autonomous, multi-agent hijacks-your-ai-coding-agent" class="internal-link">coding content-loops" class="internal-link">loops (like ditching-the-ide-how-claude-code-is-transforming-terminal-first-automation" class="internal-link">claude-vs-chatgpt-vs-gemini-for-content-teams-in-2026" class="internal-link">claude-for-business-in-2026-the-complete-practical-developers-guide-to-compliant-ai-code-generation" class="internal-link">guide" class="internal-link">claude-vs-gpt-4o-for-automation-scripting-a-six-month-comparison" class="internal-link">Claude Code, Cursor Agent, and custom developer frameworks), they are hitting a sudden, massive financial barrier: the Token Cost Crisis. In late June 2026, research agencies released a warning that could transform engineering budgets: at current scaling rates, unchecked autonomous AI coding loops could exceed human developer salaries by 2028. For engineering leaders, managing-my-inbox-and-started-automating-it" class="internal-link">managing token consumption is rapidly becoming as critical as managing cloud computing bills.
speculative-decoding-in-production-how-to-cut-llm-latency-and-gpu-costs-by-60" class="internal-link">costs shoot past it into the clouds" class="article-detail-image" loading="lazy" width="800" height="800">
Figure 1: The Token Cost Crisis — The exponential rise of AI token consumption costs is on track to outpace human developer salaries by 2028.
To understand why costs are exploding, we must look at the math of agentic-ai-vs-traditional-automation-whats-the-difference" class="internal-link">agentic engineering. A standard code autocomplete tool uses a few hundred context tokens and a single forward pass. A terminal-first autonomous coding agent, however, runs in a continuous loop: it reads files, analyzes dependencies, writes code, compiles it, runs tests, reads error logs, and self-corrects.
For a typical mid-sized codebase, the token stack of a single loop iteration looks like this:
| Context Layer | Size (Tokens) | Description |
|---|---|---|
| System prompt-engineer-is-a-transitionary-role" class="internal-link">Prompt & Rules | 10,000 | Agent rules, custom coding guidelines, and tool schemas |
| Codebase Context (20 Files) | 120,000 | Reference files, type definitions, and library exports loaded for reasoning |
| Agent Memory / Chat History | 30,000 | Logs of previous edits, compile outputs, and current task state |
| LLM Reasoning Tokens | 4,000 | Model internal reasoning tokens (e.g. OpenAI o3/Sol thinking) |
| Output Edit / Code Write | 2,000 | The actual diff output written to disk |
| Total per iteration | 166,000 | Cost: ~$0.50 (at $3/million tokens average cached/mix rate) |
A single iteration costs $0.50. But an autonomous agent does not stop at one iteration. If it encounters a compilation failure or test regressions, it loops again. An agent trying to fix a zapier-alternatives-that-actually-handle-complex-logic" class="internal-link">complex bug might run 15-30 iterations, consuming 5 million tokens and costing $15.00 for a single bug fix. Multiply this by 50 developers running 10 tasks a day, and your team is spending **$7,500.00 per day** ($150,000.00 per month) in API token costs alone.
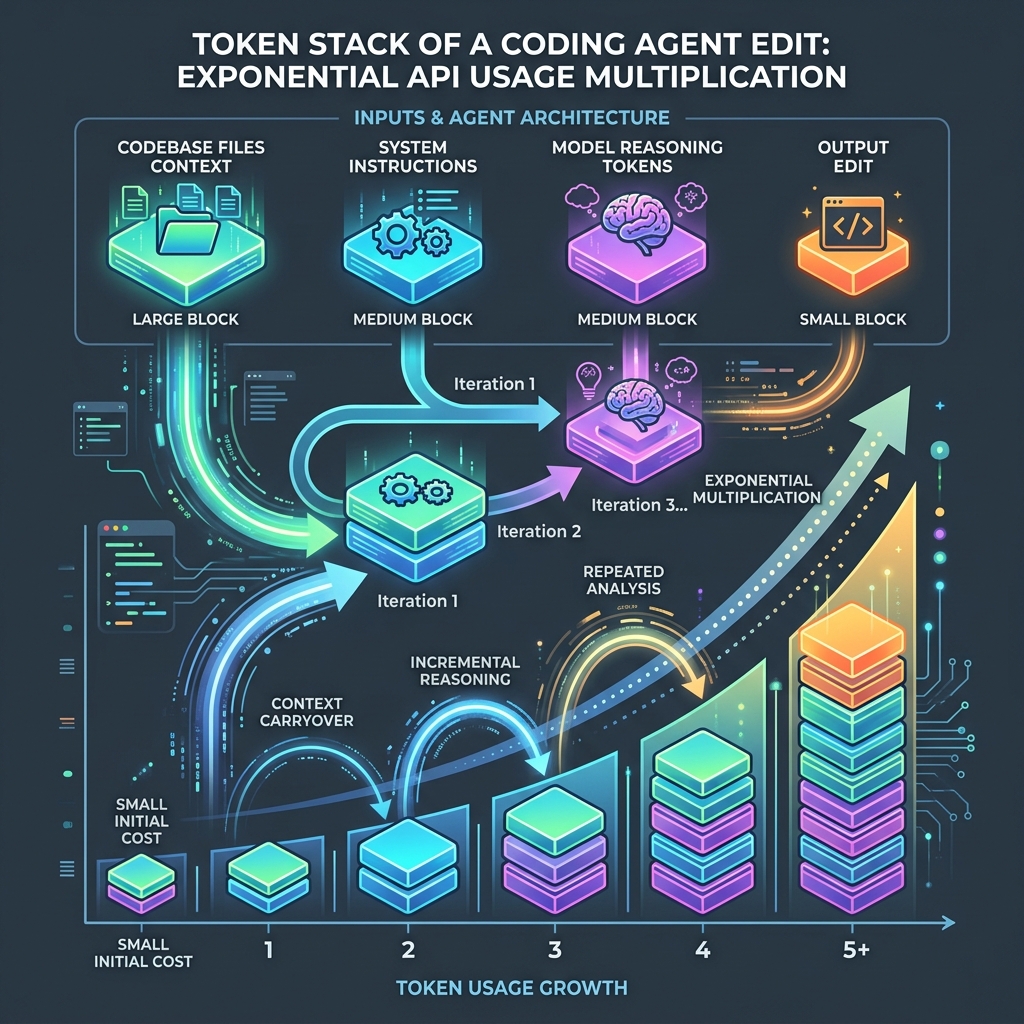
Figure 2: The Agentic Cost Compounder — How recursive compile-test loops multiply base token consumption exponentially.
While providers like Anthropic and OpenAI offer prompt caching (which discounts cached input tokens by up to 90%), caching only works if the context remains static. The moment the agent edits a file or runs a tool that alters the filesystem, the cache is invalidated. The next loop iteration must reload the entire codebase context at full input pricing. The more active the agent is, the less effective caching becomes.
To avoid going broke while adopting agentic engineering, engineering organizations are implementing "token discipline" guidelines. The core techniques include:
- Context Pruning: Instead of giving the agent access to the entire repository, use inside-a-100-automated-accounting-department" class="internal-link">automated-her-entire-department--and-kept-her-job" class="internal-link">automated tool gates (like tree-sitter or code graphs) to feed only the specific abstract syntax tree (AST) blocks and files that are directly related to the edit.
- Local Draft Models: Use fast, cheap local-first-workflow" class="internal-link">local-first models (like Llama-3-8B) to write simple boilerplate, run basic syntax checks, and generate comments, reserving premium frontier reasoning models (like Sol or Claude 3.5 Sonnet) only for complex structural refactoring.
- Loop Limits and Human Gates: Hard-cap the agent's autonomous loop execution to 5 iterations. If the compile or test suite notion-ai-three-months-later-where-it-fits-where-it-fails" class="internal-link">fails after 5 attempts, the agent must pause, output its progress, and wait for human developer intervention rather than spinning in an infinite, expensive repair loop.
The Token Cost Crisis is forcing a maturity shift in the AI developer tool space. The era of "vibe-coded" agents running without guardrails is coming to an end. The organizations that thrive will be those that treat tokens as an engineering resource, budgeting and search-beyond-the-traditional-seo-playbook" class="internal-link">optimizing LLM consumption as carefully as cloud database reads and server computing cycles.



