The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

Over the last year, a quiet transformation has occurred on the desktops of software prompt-engineer-is-a-transitionary-role" class="internal-link">engineers worldwide. The default environment for coding-agent" class="internal-link">coding assistance has moved away from public API endpoints toward local-first runtimes. At the center of this shift is Ollama. By abstracting the complexity of model compilation, quantization, and local memory management, Ollama has effectively become the "Docker of Large Language Models." For developers looking to secure their source code, eliminate network building-a-production-grade-ai-agent-the-auditing-and-governance-checklist" class="internal-link">building-a-geo-distributed-automation-pipeline-overcoming-speculative-decoding-in-production-how-to-cut-llm-latency-and-gpu-costs-by-60" class="internal-link">latency-and-legal-boundaries" class="internal-link">latency, and avoid API usage limits, Ollama is the vital interface for desktop AI engineering.
Figure 1: The Ollama Desktop Stack — running local LLM runtimes directly on developer machines to support agentic-ai-vs-traditional-automation-whats-the-difference" class="internal-link">agentic coding.
While cloud models remain larger and more capable for general-purpose tasks, local runtimes offer structural advantages that matter to working software engineers:
- Zero Latency: Routing request packets through the public internet to hosted APIs adds significant latency. Local runtimes served on localhost eliminate network overhead, delivering autocomplete tokens instantly.
- Code Privacy and Security: Many enterprise organizations enforce strict data governance rules that prohibit sending proprietary codebases to external APIs. Ollama keeps the entire code context inside-a-100-automated-accounting-department" class="internal-link">inside the developer's local machine boundary.
- Offline Reliability: Local models run without an active internet connection. A developer coding on an airplane or in a location with poor connectivity retains access to full autocomplete and debugging assistants.
- Zero Cost Scaling: Instead of paying per token for hosted API calls, local execution utilizes the GPU hardware already present on the developer's laptop, eliminating ongoing billing cycles.
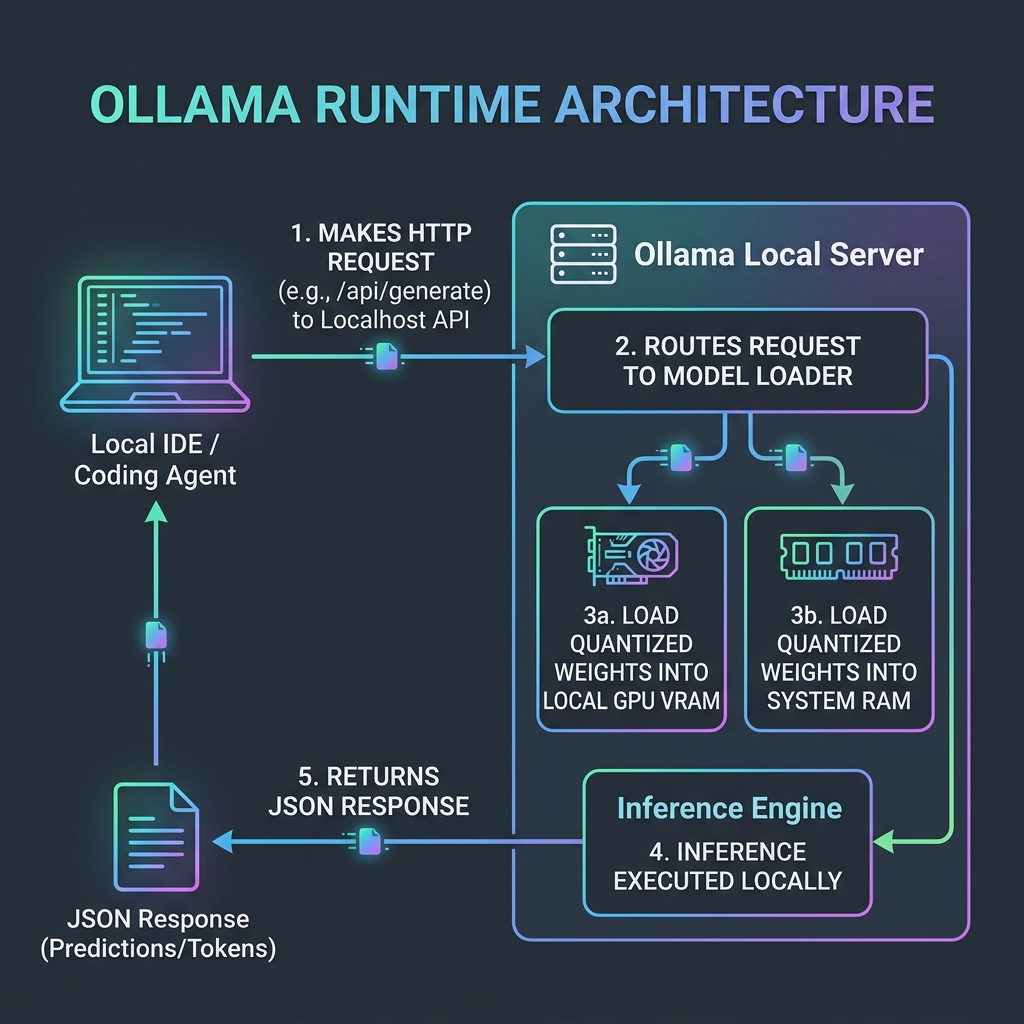
Figure 2: The Ollama Architecture — how local IDEs connect to localhost APIs to perform secure, high-speed inference.
To integrate local models into their workflow, developers are pairing Ollama with standard terminal tools and extensions. A typical local stack consists of:
| Component | Tooling | Role |
|---|---|---|
| Local LLM Runtime | Ollama | Manages model weights, zapier-alternatives-that-actually-handle-complex-logic" class="internal-link">handles quantization, and exposes a localhost API. |
| Model Tier | Qwen-2.5-Coder / Llama-3.1-8B | Underlying open-weights models optimized for code completion and instruction following. |
| IDE Interface | Cursor / VS Code with Continue.dev | Sends editor cursor context to the localhost API for inline autocomplete and chat. |
| Terminal Agent | Aider / Local coding agents | Navigates codebases, edits files, and runs git commands autonomously using local model endpoints. |
The configuration of this stack is remarkably simple. Once Ollama is installed, a developer can download and serve a specialized coding model with a single terminal command:
# Pull and serve Qwen-2.5 Coder locally
ollama run qwen2.5-coder:7bThis command automatically initializes a local API server on `http://localhost:11434`, exposing an OpenAI-compatible endpoint that any developer extension can query.
The Ollama Effect is the first step toward a broader local-first engineering philosophy. As desktop hardware continues to scale—with specialized NPU (Neural Processing Unit) silicon becoming standard on consumer laptops—the quality gap between local open-weights models and massive cloud APIs is closing. For developers, the message is clear: the future of AI engineering is local-first, private, and running directly on your desktop.


