The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

Evaluating the economics and security of Swedish and French enterprise teams self-hosting llama-3-70b-instruct.

A comparative engineering study on Cold Starts, Reserved Instances, and pay-per-second API runtimes like RunPod and Modal.

A deep dive into regulatory rules, explainability requirements, and risk levels for European code deployments.

In early 2025, the tech community was captivated by a new phrase: vibe coding. Coined to describe the experience of typing plain-English prompts into AI models like Claude or Replit and watching complete applications materialize, vibe coding promised to democratize software development. Non-technical founders built functional prototypes in an afternoon, while seasoned engineers joked about retiring their compilers. But as these prototypes migrated from local sandboxes to multi-user production environments, the vibes quickly soured. Unhandled exceptions, infinite loops, and API hallucinations led to production outages. In response, a more disciplined methodology has emerged in 2026: Agentic Engineering. This article dissects the limits of chat-based prototyping and details the concrete architecture required to build secure, autonomous coding pipelines.
Figure 1: The contrast between the relaxed flow of natural language vibe coding and the strict, automated validation structures of Agentic Engineering.
Vibe coding is fundamentally an open-loop system. The user inputs a prompt, the model outputs code, and the user copies it to their editor. If the code fails, the user copies the error back into the prompt window. This manual context-switching loop is slow, error-prone, and relies entirely on human validation. When a codebase grows beyond a single file, the model's context window fills up, leading to syntax truncation and silent failures.
By contrast, Agentic Engineering builds a closed-loop feedback system. The agent is not just a text generator; it is equipped with tools to read directories, execute commands in isolated terminals, check git status, and run unit tests. If a compile or test run fails, the agent parses the stdout, identifies the bug, rewrites the file, and runs the compiler again. The human developer moves from a manual copy-paste clerk to an architect who defines high-level constraints and approves git diffs.
| Metric | Vibe Coding (Chat-Based) | Agentic Engineering (Closed-Loop) |
|---|---|---|
| Primary Interface | Web GUI Chat / Side-Panel Plugin | Terminal Agent / Integrated Repository Loop |
| Context Management | Manual upload / copy-paste | Automated directory mapping & local indexing |
| Validation Strategy | Vibe Check (Visual inspection on runtime) | Test-Driven Automation (Unit, integration, and lint checks) |
| Production Security | Low (High risk of injecting vulnerability) | High (Pre-commit hooks, sandboxed evaluations) |
| Maintenance Cost | High (Tech debt accumulates rapidly) | Low (Structured refactoring and strict style rules) |
To implement Agentic Engineering, developers must establish an automated execution loop that compiles, runs tests, and pipes logs back to the LLM. Below is a Python orchestration script showing how to run a test harness autonomously, capturing stdout errors to drive self-healing code edits:
import subprocess
import json
def execute_validation_cycle(test_command, file_to_fix):
# 1. Run local test suite
print(f"[Agentic OS] Running: {test_command}")
result = subprocess.run(test_command, shell=True, capture_output=True, text=True)
# 2. Check if tests passed
if result.returncode == 0:
print("[Agentic OS] Build validated successfully!")
return True
# 3. If failed, capture output log and request correction
print("[Agentic OS] Validation failed. Parsing stack trace...")
error_log = result.stderr or result.stdout
# In a real system, the error log and code are sent to the LLM agent
corrected_code = request_llm_fix(file_to_fix, error_log)
# 4. Write fix to file and retry execution
with open(file_to_fix, "w", encoding="utf-8") as f:
f.write(corrected_code)
print("[Agentic OS] Fix written. Restarting verification loop...")
return False
def request_llm_fix(filepath, error_trace):
# Simulated correction - in production, this queries Claude 3.5 Sonnet
return "def compute_total(items):\n return sum(item.price for item in items if item is not None)"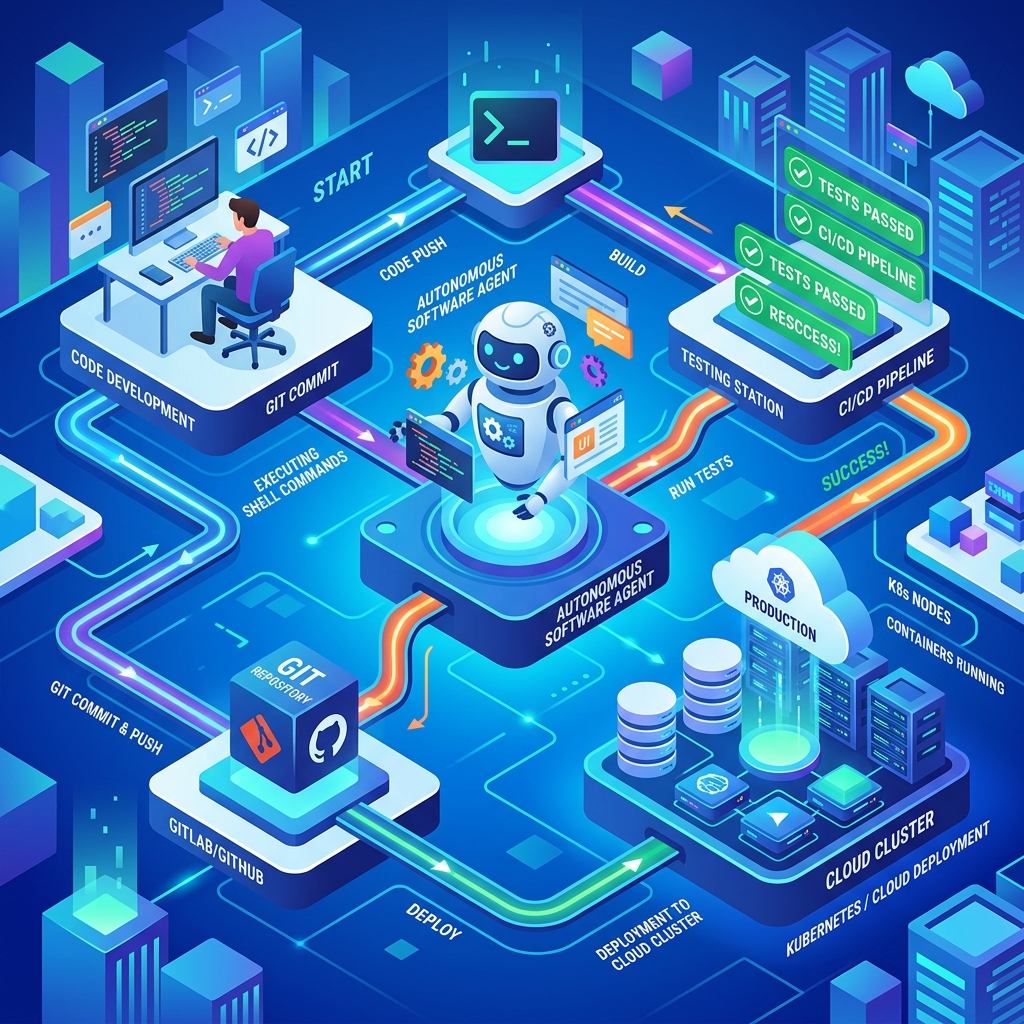
Figure 2: The closed-loop validation pipeline showing automated test parsing, self-healing code modifications, and git staging.
One of the primary dangers of letting autonomous agents write code directly to your codebase is the erosion of architecture patterns. An agent, left to its own devices, will write whatever code satisfies the immediate test case, often introducing duplicate utilities, messy abstractions, or security vulnerabilities.
To mitigate this, teams are standardizing on `.cursorrules` or `.agentrules` configuration files. These files act as system prompts that are automatically injected into the agent's context. By defining strict guidelines (e.g., "Use TypeScript only," "Do not use external CSS libraries," "Enforce US English spelling," "Never use third-party CDN libraries"), you ensure that the generated code conforms to your engineering team's standards, preventing the accumulation of massive AI tech debt.
Vibe coding serves a vital role: it lowers the barrier to entry and allows teams to validate ideas in hours instead of weeks. But when it comes to shipping production systems, developers must transition to Agentic Engineering. By equipping AI agents with terminal tools, sandboxing their executions, and wrapping them in automated validation scripts, organizations can capture the speed of generative AI without sacrificing the security and quality of their software engineering processes.