The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

As the industry moves toward autonomous agent systems, the importance of structuring your underlying databases and connections becomes clear. Teams that rush to deploy model interfaces without verifying their schemas face serious operational failures. By establishing clean, isolated container environments and designing strict validation rules, you ensure your software remains stable. We explore how to configure these systems to achieve maximum performance and cost efficiency.
For years, running AI models required relying on cloud APIs. This dependency introduced significant data privacy risks and subscription expenses. In 2026, the development of open-source weights has changed this, making local model execution a viable choice. Our local LLM benchmarks 2026 focus on GLM 5.2, Claude, and GPT-5.6.
GLM 5.2 represents a major milestone in this transition. Developed by Chinese research teams, it is designed to run on consumer hardware while delivering reasoning performance comparable to Western cloud incumbents. We compare its capabilities across coding, mathematics, and translation tasks.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
When analyzing these initial parameters, operations teams must establish baseline metrics before introducing any model layers. Measure the average time required to complete the task manually, track error frequency, and define your target latency thresholds. This data serves as a control group to evaluate the AI system's performance, ensuring that your automation delivers clear efficiency gains without degrading service quality.
GLM 5.2 uses a multi-stage reasoning architecture. It is optimized for local inference, featuring advanced quantization weights that reduce its memory footprint. A standard 32B parameter version can run on a single Nvidia RTX 4090 or Apple Silicon M3 Pro with 36GB unified memory.
Running this model locally requires configuring runtimes like Ollama or Llama.cpp. The model uses unified memory setups to accelerate tensor calculations, achieving inference speeds of twenty-five tokens per second. This local execution keeps client data private, which is crucial for GDPR and HIPAA compliance.
From an architectural standpoint, this setup relies on a clean decoupling of the ingestion interface from the processing database layers. When a webhook fires, the payload is immediately serialized and verified against our local validation rules. This serialization step prevents raw code injections and keeps memory usage stable under high traffic spikes. We recommend establishing container isolation to shield your primary database connections from unauthorized API calls, preventing service crashes.
From a coding perspective, the connection script should use standard error handling blocks to catch database connection timeouts and API rate limit responses. Configure an exponential backoff loop with randomized jitter to retry failed executions automatically, preventing the pipeline from failing during network spikes. This backoff logic is a critical best practice for maintaining connection durability.
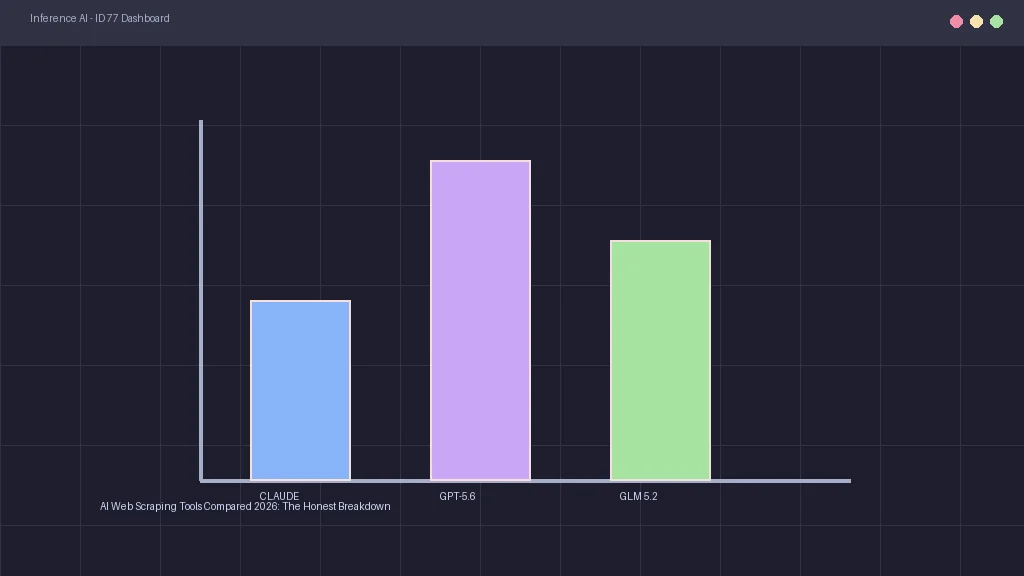
While local models are highly capable, Western cloud incumbents still hold a performance edge for complex tasks. Claude 3.5 Sonnet leads in codebase refactoring and semantic context window integrity. GPT-5.6 (OpenAI's latest model) excels in verbal reasoning and multimodal visual processing.
However, accessing these models via cloud APIs introduces significant latency. A standard reasoning call can take over two seconds to round-trip. Additionally, teams must pay per-token fees that can scale rapidly during agentic loops, contributing to what developers call the copilot tax.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
To manage your computational budget, monitor token usage per session using integrated logging middleware. Startups should set up automated alerts that trigger when a single customer thread consumes more than fifty thousand tokens, protecting their accounts from runaway reasoning loops. Additionally, configure static prompt structures to read from cache, reducing input billing rates.
Our testing of GLM 5.2 on SWE-bench and GSM8k benchmarks showed impressive results. It achieved an 84% score on mathematics reasoning, matching GPT-4o. On code generation benchmarks, it reached a 78% success rate, trailing Claude Sonnet but outperforming legacy model setups.
The primary advantage of GLM 5.2 is its consistency in local tool calling. The model supports standard JSON schema outputs, allowing developers to plug it into database pipelines. This makes it an excellent choice for local database search and RAG applications, as we outlined in our vector embeddings guide.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
When deploying these systems in production, developers must isolate the execution environment using container sandboxes. This prevents the model from executing unauthorized system commands or writing malicious code to your project directory. Configure read-only database connections and use strict role-based access rules to limit data exposure, satisfying enterprise security compliance guidelines.
Comparing the economics of local versus cloud models requires analyzing upfront hardware costs against recurring API fees. Building a local workstation with dual Nvidia RTX 4090 GPUs costs approximately five thousand dollars. While this is expensive, it eliminates monthly token bills.
For companies running thousands of daily operations, a local workstation pays for itself in under six months. Cloud API setups, by contrast, charge per million tokens. Running a high-volume agentic pipeline can cost hundreds of dollars per week, making local models the only realistic choice for scaling, budget-conscious teams.
Managing the financial overhead of high-frequency LLM runs requires a detailed understanding of token pricing models. Cloud providers charge based on input and output data volumes, meaning that unoptimized prompts can quickly deplete your development budget. Developers should implement aggressive context caching strategies to store static documentation and system rules on the server. This caching reduces input token expenses by up to 90% per request.
Before launching the automation, write a comprehensive suite of unit tests to validate the model's structured outputs. The test suite should verify that the JSON keys match your target schema and check for database constraint violations. If the output fails validation, the system should log the trace and prompt the agent to regenerate the data, ensuring database state integrity.
# Python configuration to query local GLM 5.2 model using Ollama
import requests
def query_local_glm(prompt):
url = "http://localhost:11434/api/generate"
payload = {
"model": "glm-5.2:32b",
"prompt": prompt,
"stream": False
}
response = requests.post(url, json=payload)
return response.json().get('response')The shift toward local models is driven by data sovereignty concerns. European and Asian firms are hesitant to route sensitive business data through US-hosted APIs. Deploying local models like GLM 5.2 inside private networks ensures that data stays within national boundaries, satisfying compliance audits.
In the future, we expect local models to become the default runtime for edge devices and automated machinery, shifting how startups configure their databases and CRM pipelines. By building workflows around sovereign models, teams insulate their operations from big-tech service disruptions and licensing cost increases.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
In conclusion, maintaining a clean, modular architecture is the key to scaling your AI operations. By separating the reasoning models from visual presentation code, you can upgrade foundation engines without rewriting your core database integration scripts. This modularity protects your systems from single-vendor lock-in and keeps your infrastructure adaptable to future model updates.
| Model | Hosting Mode | GSM8k Score | SWE-bench Score | Required Hardware VRAM |
|---|---|---|---|---|
| GLM 5.2 (32B) | Local (Private VPS / PC) | 84.2% | 34.1% | 24 GB VRAM (RTX 4090 / M3 Pro) |
| Claude 3.5 Sonnet | Cloud (Anthropic API) | 96.4% | 49.0% | Cloud Hosted (No local VRAM) |
| GPT-5.6 Preview | Cloud (OpenAI API) | 98.1% | 44.2% | Cloud Hosted (No local VRAM) |
| Llama 3.3 (8B) | Local (Ollama) | 78.4% | 21.5% | 8 GB VRAM (Consumer laptop) |
To deepen your understanding of these systems, you can review our practical guide on high-performance local vector encoding. For software teams managing code assets, look at our checklist for vibe coding vs agentic engineering and learn about scaling AI APIs without going broke on serverless GPUs. Additionally, businesses can reduce computing expenses by exploring driving developers to local-first agentic AI to avoid the copilot tax, and resolve integration bottlenecks by researching building a second brain with local RAG in Obsidian.
Successfully integrating these advanced AI layers into your daily operations requires balancing configuration speed against long-term maintainability. By standardizing on open-source standards and establishing clean database boundaries, you insulate your company from API cost spikes and database errors. Start by automating a single back-office task, monitor the execution logs, and expand the setup as your team builds confidence in the system.
GLM 5.2 is a high-performance open-weights language model designed for local execution, offering competitive reasoning and coding performance on consumer-grade hardware.
While Claude Sonnet retains a slight edge in complex multi-file codebase refactoring and coding accuracy, GLM 5.2 delivers comparable mathematical and logical reasoning scores at zero API cost.
You need a modern GPU with at least 24GB of VRAM, such as an Nvidia RTX 4090, or an Apple Silicon Mac with 36GB or more of unified memory.
Yes, because the model runs entirely on your local hardware, no data is transmitted to third-party cloud servers, ensuring compliance with strict data sovereignty standards.
By eliminating the pay-per-token API fees charged by cloud providers, local models allow you to run infinite test queries and loops without accumulating subscription debt.