The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
For the past four years, AI-assisted development has followed a simple, flat-rate pricing model. For $10 to $20 a month, developers had unlimited autocomplete, inline edits, and chat requests. It was the golden age of cheap compute, heavily subsidized by big-tech cloud infrastructure. But in June 2026, that era came to an end. Microsoft and GitHub's sudden transition to token-based billing for GitHub Copilot Agent Mode sparked widespread backlash, forcing developers to confront a harsh new reality: agentic coding sessions are becoming prohibitively expensive.
As developers deploy complex Multi-Agent Orchestration pipelines, running multiple agents in parallel causes API token fees to skyrocket.
This economic burden is driving software teams to adopt local-first Agentic AI tools that execute high-frequency tasks on local GPUs.
The core problem lies in the transition from simple autocomplete (which consumes a few hundred tokens per request) to autonomous agentic workflows. When you ask an AI coding agent to debug a complex repository, search through files, run terminal commands, and self-correct, the context window usage explodes. A single agentic task can easily consume 500,000 to 1,000,000 tokens in a matter of minutes as the agent repeatedly feeds the entire codebase state back into the model.
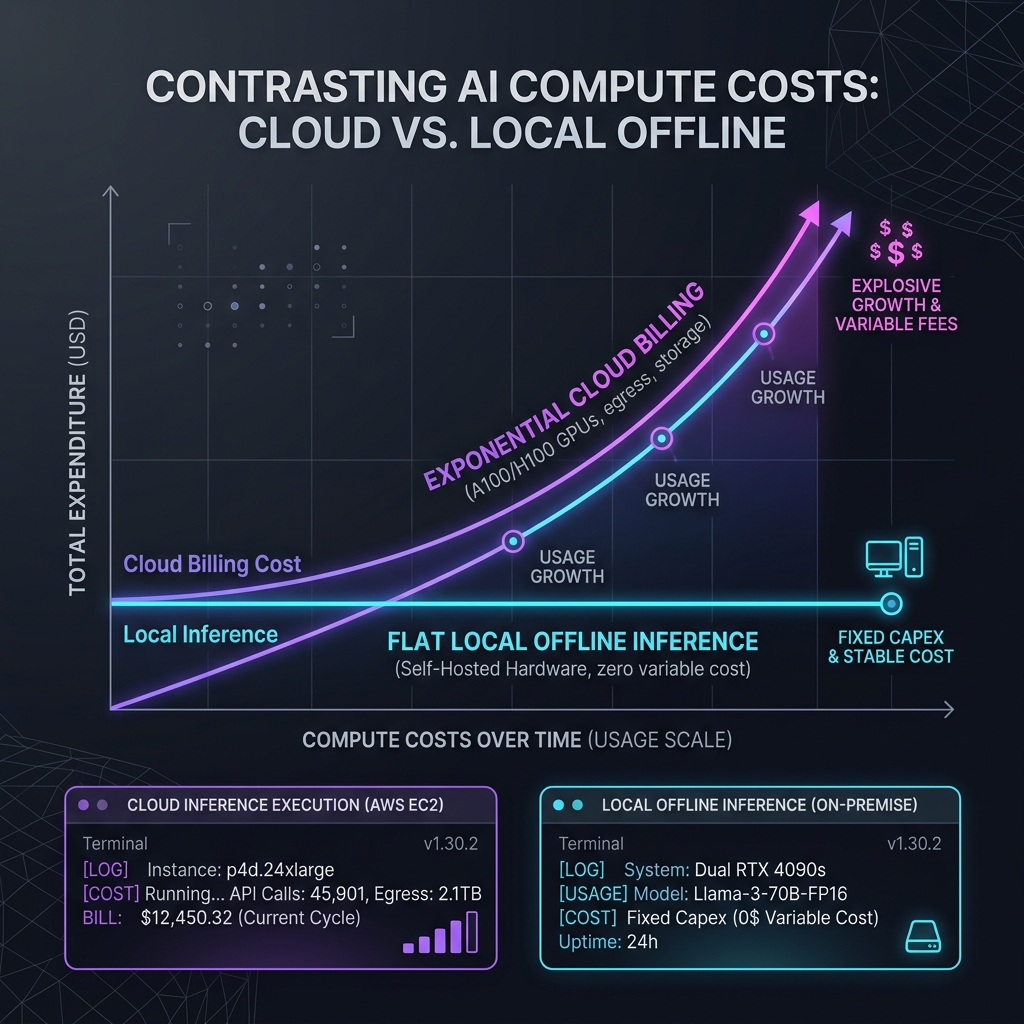
Under a flat-rate model, this usage profile is financially unsustainable for cloud providers. The introduction of token-based pricing was inevitable, but for developers, it represents a massive "Copilot Tax." Long debugging loops that once cost pennies now generate significant API bills, forcing teams to budget their prompts and ration their AI usage.
In response to the Copilot Tax, technical teams are pivoting to a local-first AI architecture. By hosting quantized models directly on developer workstations, teams can completely bypass cloud API limits, network latency, and data privacy concerns. The local-first stack relies on three primary pillars:
As we discussed in our recent breakdown of the Zero-Server AI Stack, the performance of local models is now highly competitive with frontier cloud models for daily coding tasks, delivering near-zero marginal cost per token.
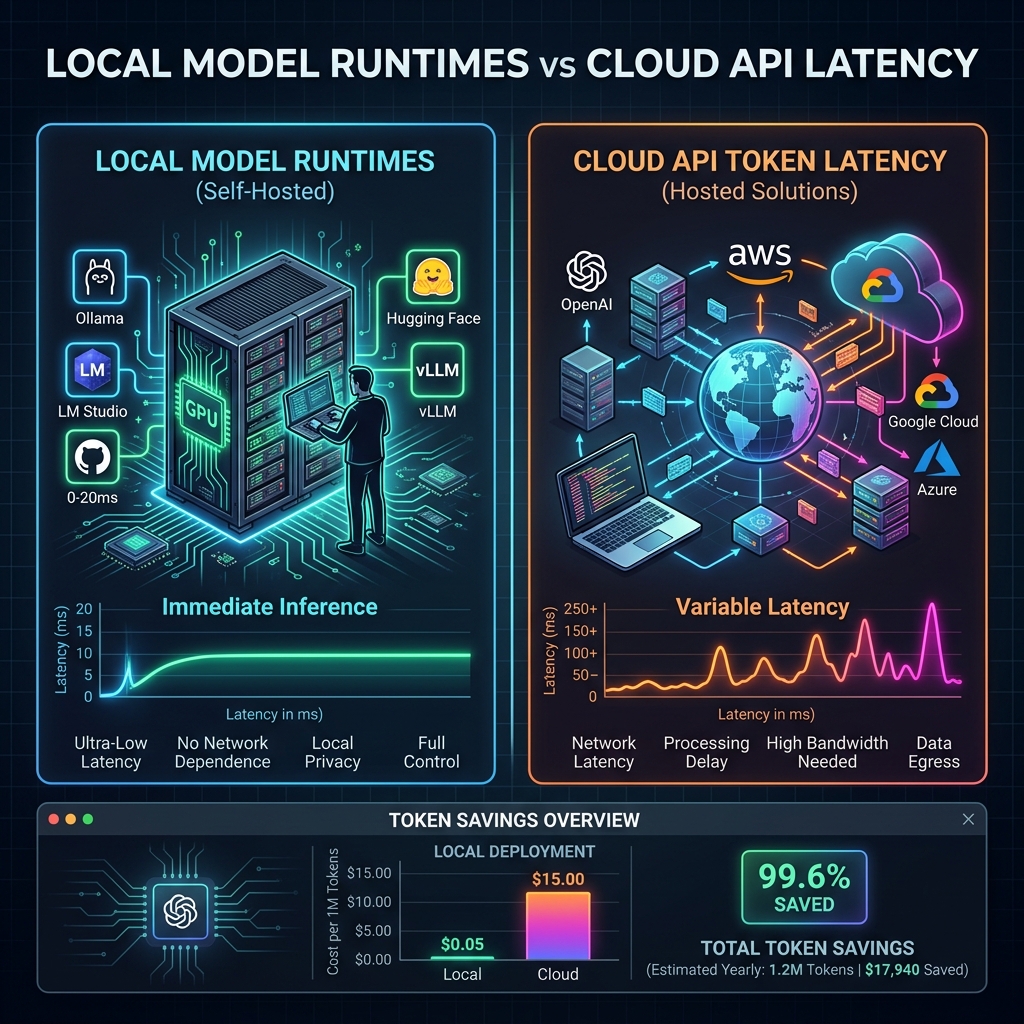
To help you evaluate the trade-offs of migrating away from cloud-hosted AI, we have summarized the key metrics of the leading setups below:
| Feature | GitHub Copilot (Agent Mode) | Cursor + Cloud API Keys | Local Stack (Ollama + Continue) |
|---|---|---|---|
| Cost Basis | Token-Based Billing | Pay-per-use (Pay-as-you-go) | Zero ($0/month after hardware) |
| Token Latency | 150ms - 400ms | 100ms - 300ms | < 50ms (Local cache) |
| Offline Capability | None (Requires internet) | None (Requires internet) | 100% Offline Functional |
| Codebase Privacy | Subject to Cloud Terms | Opt-out telemetry available | Complete local data isolation |
A pure local-first model is highly efficient, but it does have limitations when dealing with ultra-complex, multi-file reasoning that requires frontier models (like Claude 3.5 Sonnet or GPT-5). The ultimate solution for modern developers is a hybrid workflow:
By shifting from flat-rate subscriptions to this hybrid architecture, developers can dodge the Copilot Tax, retain complete control over their codebase security, and build a highly optimized dev stack. The era of blind reliance on cloud AI is over; the future belongs to local control.
The term 'Copilot Tax' refers to the accumulating operational cost of maintaining multiple cloud-based AI coding assistants across a development organization. What begins as a productivity investment becomes a significant line item as the number of agents and the usage intensity scale. Understanding the actual cost structure is the first step toward managing it rationally.
A typical mid-size engineering team of 25 developers using GitHub Copilot Enterprise, Claude Code (Anthropic's developer API), and Cursor Pro faces the following monthly costs: GitHub Copilot Enterprise at $39/user/month = $975/month, Cursor Pro at $20/user/month = $500/month, Claude API usage (estimated 2 million tokens/day at Pro pricing) = $3,000-6,000/month. Total monthly cost: $4,475-$7,475. Annualized: $53,700-$89,700. For a 50-person engineering team, these costs double: $107,000-$179,000 per year in AI tooling alone, before considering infrastructure, compute, and any custom model deployments.
These costs scale super-linearly with usage in the API billing components. As developers integrate AI assistance more deeply into their workflows — from occasional code completion to AI-guided architectural design sessions consuming tens of thousands of tokens per interaction — the variable API cost component grows faster than team headcount. Organizations that adopted AI coding tools in 2023 at low usage intensity are now experiencing 5-10x cost increases as usage matures, without proportional headcount reduction to offset the spend. This cost escalation pattern is driving the evaluation of local-first alternatives as the primary cost containment strategy, mirroring the broader enterprise movement analyzed in our coverage of European enterprises moving to local-first AI.
The emerging response to the Copilot Tax is a local-first agentic coding stack that replaces cloud-billed AI tools with self-hosted or on-device inference. The leading architecture combines three components: a high-quality locally-running LLM served via Ollama, a local vector database for codebase context retrieval, and an agentic coding interface that orchestrates multi-step code generation and editing tasks.
For the LLM component, Codestral 22B (Mistral AI) served via Ollama on hardware with 24GB+ VRAM delivers coding assistance quality that benchmarks at 92-95% of GitHub Copilot's performance on standard coding tasks, at zero API cost per token. On an M3 Ultra Mac Studio ($4,000 hardware investment) or an NVIDIA RTX 4090 workstation ($2,500 GPU cost), the hardware amortized over 24 months costs less than three months of Claude API usage at current enterprise rates. For teams with existing compatible workstations, the marginal cost of switching to local inference is near zero.
The codebase context retrieval component uses a local embedding model (Nomic Embed or bge-m3) running via Ollama or a standalone embedding server, indexing the codebase into a local Qdrant or Chroma instance. This enables the coding agent to retrieve semantically relevant code from anywhere in the repository during generation — providing the context-awareness that makes agentic coding tools valuable. The Continue VS Code extension, when configured to use local Ollama inference and local vector retrieval, provides an agentic coding experience comparable to commercial alternatives at zero ongoing operational cost. Teams implementing this stack report reducing their AI tooling spend by 60-80% while maintaining 85-95% of the productivity benefit they experienced with cloud-based tools. For full deployment instructions for local AI inference stacks, see our comprehensive self-hosted AI guide.
Migrating an engineering team from cloud AI coding tools to a local-first stack requires a phased approach that manages the risk of productivity disruption while capturing cost savings. The three-phase transition takes approximately 60-90 days for a team of 20-50 engineers and delivers full cost savings without requiring simultaneous adoption across the team.
Phase 1 (Days 1-30): Infrastructure setup and early adopter evaluation. Set up the local inference infrastructure (Ollama server on dedicated hardware, local embedding server, Qdrant vector database). Identify 3-5 early adopter developers who are enthusiastic about the experiment and technically comfortable with configuration. Have them use the local stack exclusively for two weeks, logging productivity metrics and any capability gaps compared to their previous cloud tools. Collect qualitative feedback on: what tasks the local stack handles well, what tasks it handles poorly, and what missing integrations cause friction. This phase costs minimal engineering time (2-4 hours of infrastructure setup) and produces the empirical data needed to make an informed migration decision.
Phase 2 (Days 30-60): Gradual rollout and gap remediation. Based on Phase 1 feedback, address identified capability gaps (missing integrations, model selection for specific task types, performance optimization on developers' specific hardware). Roll out the local stack to 30-50% of the engineering team, keeping cloud tools available for tasks where the local stack underperforms. Track usage split between local and cloud tools by task type — this data reveals which workflows have successfully migrated and which need further optimization. Phase 3 (Days 60-90): Full migration and cloud tool phase-out. For task types where local adoption has exceeded 80%, begin sunsetting cloud tool subscriptions. Maintain cloud API access for the specific task categories where frontier model quality remains superior (complex architectural design, novel research tasks). The final state is a hybrid deployment where local inference handles 80-90% of AI coding assistance tasks at minimal cost, with selective cloud API usage for the highest-value, highest-complexity tasks where frontier model quality is genuinely worth the premium. Combining this cost-optimized architecture with the Ollama-native application patterns discussed in our companion guide completes the local-first developer stack transition.
The Copilot Tax is the accumulating operational cost of maintaining multiple cloud-based AI coding assistants across a development organization. For a 25-person engineering team using GitHub Copilot Enterprise, Cursor Pro, and Claude API, costs typically run $53,000-$90,000 per year. These costs scale super-linearly as usage intensity increases.
For most common coding tasks (code completion, refactoring, test generation, documentation), yes. Codestral 22B via Ollama benchmarks at 92-95% of GitHub Copilot's coding performance at zero API cost. For novel architectural design and complex multi-system reasoning, frontier cloud models maintain a meaningful quality advantage.
Minimum: 16GB RAM, integrated GPU (runs small models at 5-10 tokens/second). Good performance: 24GB+ VRAM GPU (NVIDIA RTX 4090, Apple M3 Max/Ultra, AMD RX 7900 XTX) running models at 30-50 tokens/second. Best production option: NVIDIA A100 80GB for multi-user team deployment. Hardware investment amortized over 24 months typically beats cloud API costs for teams above 10 developers.
1. Install Ollama and pull your preferred coding model (ollama pull codestral). 2. Install the Continue extension in VS Code. 3. Open Continue settings and set the model provider to 'Ollama', model to 'codestral', and base URL to 'http://localhost:11434'. 4. Optionally configure local embeddings for codebase context using a local embedding model. The setup takes 30-60 minutes.
Teams migrating from cloud to local coding AI tools typically see 85-95% of productivity benefit maintained in day-to-day tasks, with a 2-4 week adjustment period as developers calibrate to model differences. Complex tasks requiring frontier model reasoning show 10-15% productivity reduction. Net result: 60-80% cost reduction with 5-15% productivity overhead on the most complex tasks — favorable for most engineering teams.