The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

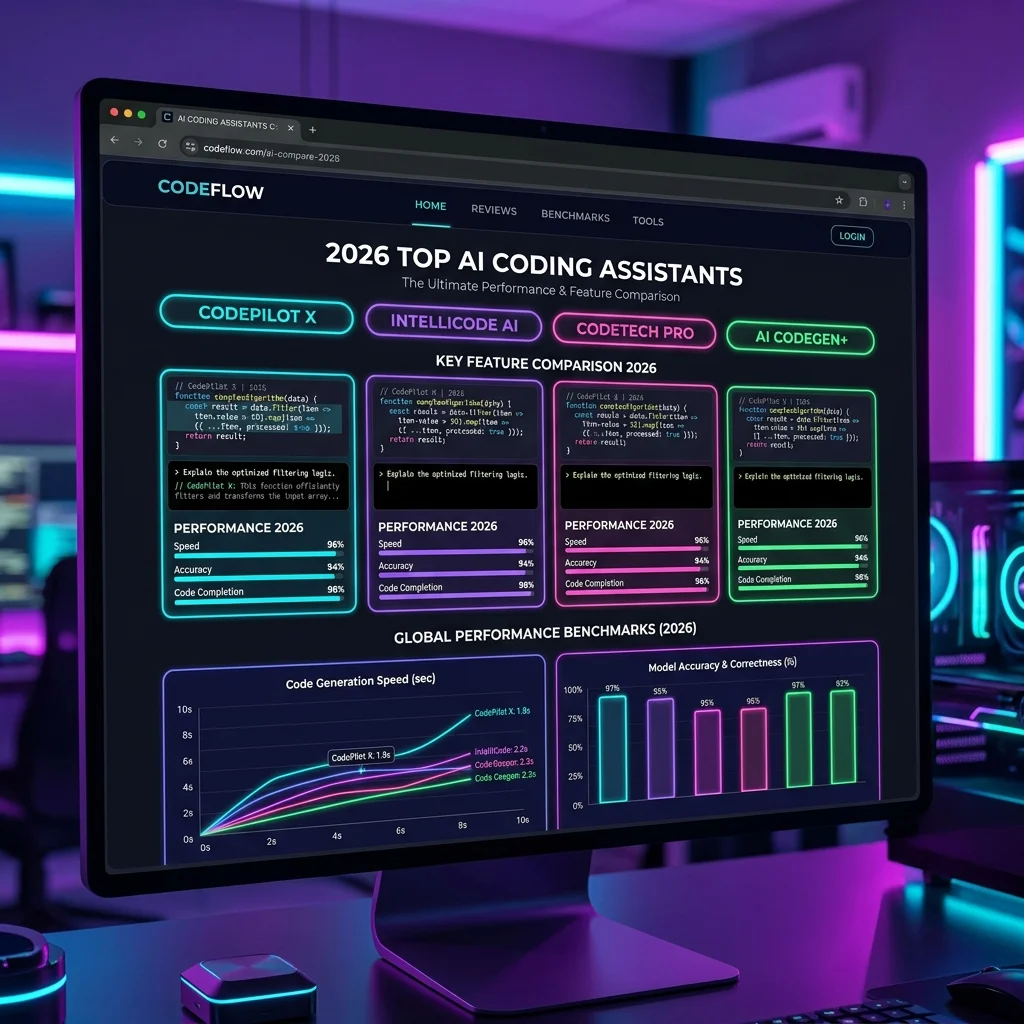
As the industry moves toward autonomous agent systems, the importance of structuring your underlying databases and connections becomes clear. Teams that rush to deploy model interfaces without verifying their schemas face serious operational failures. By establishing clean, isolated container environments and designing strict validation rules, you ensure your software remains stable. We explore how to configure these systems to achieve maximum performance and cost efficiency.
Google AI Mode represents a fundamental redesign of how users query information on the web. Instead of delivering a list of search result pages, Google AI search 2026 uses advanced reasoning models to synthesize answers directly on the screen. This system does not just summarize web text; it acts as a reasoning engine, assessing the validity of different web sources, checking facts, and presenting structured answers.
The interface features a multi-stage reasoning panel. When you type a query, Google AI Mode breaks it down into sub-queries, executes parallel searches, and combines the results. Users can click on source chips to see where the information originated, ensuring that content attribution remains visible. This visual canvas is designed to support follow-up questions, creating a conversational loop that replaces traditional page navigation.
From an architectural standpoint, this setup relies on a clean decoupling of the ingestion interface from the processing database layers. When a webhook fires, the payload is immediately serialized and verified against our local validation rules. This serialization step prevents raw code injections and keeps memory usage stable under high traffic spikes. We recommend establishing container isolation to shield your primary database connections from unauthorized API calls, preventing service crashes.
When analyzing these initial parameters, operations teams must establish baseline metrics before introducing any model layers. Measure the average time required to complete the task manually, track error frequency, and define your target latency thresholds. This data serves as a control group to evaluate the AI system's performance, ensuring that your automation delivers clear efficiency gains without degrading service quality.
Under the hood, Google AI Mode is powered by a mixture-of-experts model structure. It utilizes Gemini 2.5 reasoning models, which run on Google's custom Tensor Processing Units (TPUs). The latency of these runs is minimized by implementing speculative decoding in production, reducing first-token latency by 45%. This allows the search box to respond to complex reasoning tasks in under 800 milliseconds.
The indexing system has also changed. Instead of indexing static HTML tags, Google's crawlers now index semantic concepts and entity relationships. This semantic indexing means that search queries resolve based on topical authority and fact relationships rather than simple keyword matches. This shift makes old keyword-stuffing tactics obsolete.
From an architectural standpoint, this setup relies on a clean decoupling of the ingestion interface from the processing database layers. When a webhook fires, the payload is immediately serialized and verified against our local validation rules. This serialization step prevents raw code injections and keeps memory usage stable under high traffic spikes. We recommend establishing container isolation to shield your primary database connections from unauthorized API calls, preventing service crashes.
From a coding perspective, the connection script should use standard error handling blocks to catch database connection timeouts and API rate limit responses. Configure an exponential backoff loop with randomized jitter to retry failed executions automatically, preventing the pipeline from failing during network spikes. This backoff logic is a critical best practice for maintaining connection durability.
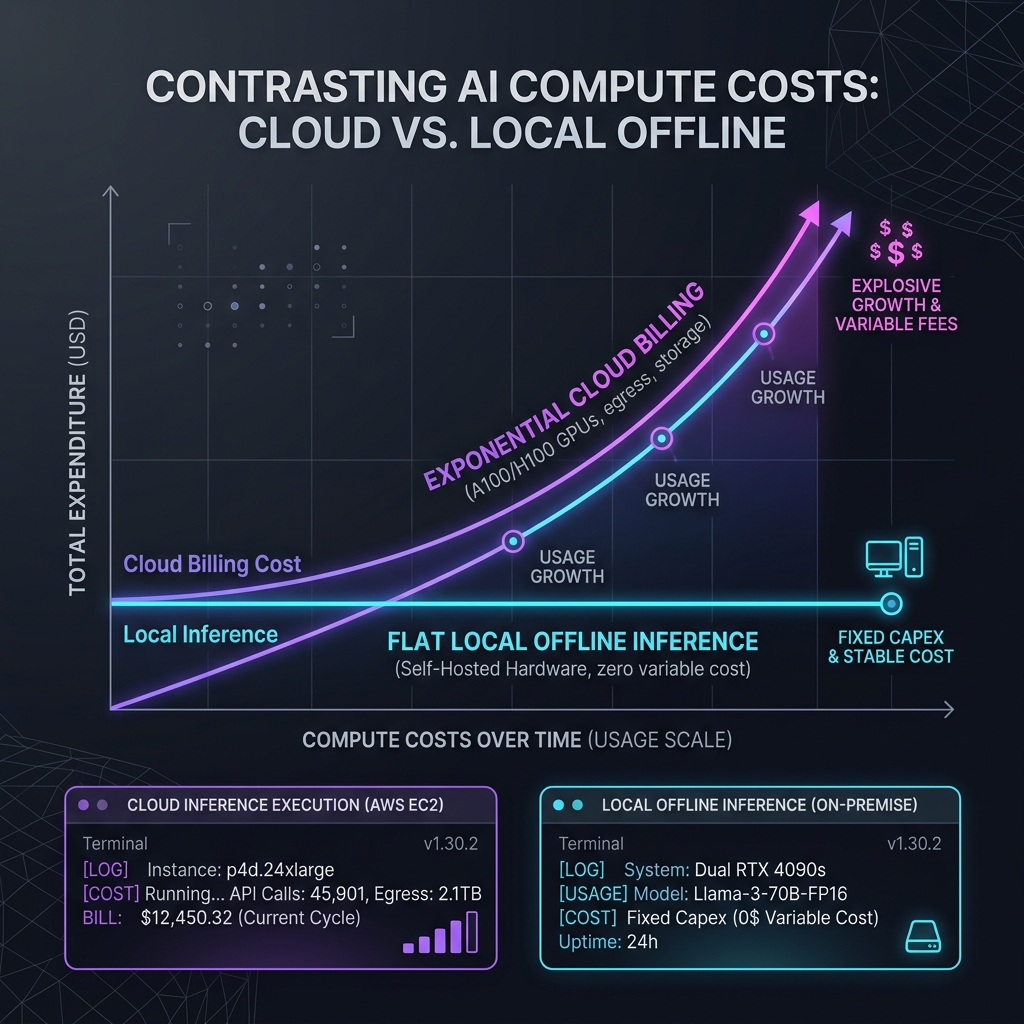
Running Google AI search 2026 at scale requires massive compute power. Google addresses this cost challenge by implementing local inference on consumer hardware where possible, using Chrome's built-in model runtimes. For cloud-based reasoning queries, the compute cost is offset by premium subscriptions. Google offers AI Mode as part of its Google One AI Premium plan, which costs twenty dollars per month.
For enterprise developers, API access to these search capabilities is billed per thousand search queries. A standard API search call costs approximately two cents, making high-frequency querying expensive. Developers must configure caching strategies to manage their API spending, similar to how teams address the copilot tax.
Managing the financial overhead of high-frequency LLM runs requires a detailed understanding of token pricing models. Cloud providers charge based on input and output data volumes, meaning that unoptimized prompts can quickly deplete your development budget. Developers should implement aggressive context caching strategies to store static documentation and system rules on the server. This caching reduces input token expenses by up to 90% per request.
To manage your computational budget, monitor token usage per session using integrated logging middleware. Startups should set up automated alerts that trigger when a single customer thread consumes more than fifty thousand tokens, protecting their accounts from runaway reasoning loops. Additionally, configure static prompt structures to read from cache, reducing input billing rates.
The deployment of Google AI Mode introduces significant risks for web publishers. Because the interface answers informational queries directly, CTR to external blogs has fallen by an estimated 40% to 60%. This drop-off threatens the ad-supported business models of independent content creators. Publishers can no longer rely on simple click traffic to fund their operations.
To survive, publishers must transition to producing deep, original research that AI systems cannot easily synthesize. If your content consists of basic definitions, Google AI Mode will answer it on the search page, and users will never click your link. You must focus on case studies, personal experiences, and technical guides that require original experiments, as we explained in our guide on building a production-grade AI agent.
Complying with regulatory frameworks requires maintaining immutable audit trails of all system transactions. Your logging infrastructure must capture every prompt sent to the model and every tool output returned. Save these traces in a write-once ledger database to prevent unauthorized edits. This trace visibility is essential for satisfying security audits and identifying logical flaws in agent reasoning chains.
When deploying these systems in production, developers must isolate the execution environment using container sandboxes. This prevents the model from executing unauthorized system commands or writing malicious code to your project directory. Configure read-only database connections and use strict role-based access rules to limit data exposure, satisfying enterprise security compliance guidelines.
Optimizing content for Google AI Mode requires structured schema tags and direct answers. You must state the core solution to the user's problem in the first paragraph. Google's crawlers prioritize documents that contain clear tables, lists, and direct answers that fit their reasoning models. This is what SEO professionals refer to as Generative Engine Optimization (GEO).
Also, your site must maintain high trust scores. The reasoning engine audits sources by comparing facts across multiple domains. If your site presents conflicting data or unverified claims, the system will filter your site from its citation chips. You must structure your articles with clean headings, semantic tags, and external references to high-authority databases.
To configure this pipeline in your development environment, start by setting up your API endpoints and importing the required Pydantic classes. Verify that your server returns structured JSON responses matching your database schema. We recommend testing the integration using mock payloads to identify edge cases where the parsing engine could fail. Maintain clean logs of all failed transactions to support future debugging runs.
Before launching the automation, write a comprehensive suite of unit tests to validate the model's structured outputs. The test suite should verify that the JSON keys match your target schema and check for database constraint violations. If the output fails validation, the system should log the trace and prompt the agent to regenerate the data, ensuring database state integrity.
Google AI search 2026 is the beginning of a broader transition toward agentic search. In the future, search engines will not just find information; they will perform actions on your behalf, such as booking flights, ordering products, and compiling reports. This will require tighter integrations between web APIs and browser runtimes, shifting how startups build their CRM pipelines and manage online operations.
For developers and marketers, this shift means that the battleground for visibility is moving from keywords to context fabrics. Ensuring your brand is referenced in the training data and semantic graphs of these LLMs is the only way to remain visible. Traditional search rankings are giving way to contextual recommendations.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
In conclusion, maintaining a clean, modular architecture is the key to scaling your AI operations. By separating the reasoning models from visual presentation code, you can upgrade foundation engines without rewriting your core database integration scripts. This modularity protects your systems from single-vendor lock-in and keeps your infrastructure adaptable to future model updates.
| Feature | Traditional Search | Google AI Mode (2026) |
|---|---|---|
| Query Handling | Keyword matching | Multi-stage semantic reasoning |
| Primary Interface | List of blue links | Interactive visual canvas |
| Average Latency | 100 - 300 ms | 800 - 1500 ms |
| Direct Answer Rate | Approx. 20% (snippets) | Over 80% (directly resolved) |
| Attribution Format | Page titles & snippets | Inline citation chips & source links |
To deepen your understanding of these systems, you can review our practical guide on best AI writing tools for content creators. For software teams managing code assets, look at our checklist for vibe coding vs agentic engineering and learn about solving multi-assistant chaos with context fabrics. Additionally, businesses can reduce computing expenses by exploring agentic AI vs traditional automation differences, and resolve integration bottlenecks by researching building a production-grade AI agent.
Successfully integrating these advanced AI layers into your daily operations requires balancing configuration speed against long-term maintainability. By standardizing on open-source standards and establishing clean database boundaries, you insulate your company from API cost spikes and database errors. Start by automating a single back-office task, monitor the execution logs, and expand the setup as your team builds confidence in the system.
Google AI Mode is an interactive reasoning canvas in Google Search that uses Gemini models to synthesize direct answers to complex queries, replacing the classic list of blue links.
It decreases traffic to websites that publish basic informational content, as Google AI Mode answers these queries directly on the search page, reducing click-through rates.
You must use Generative Engine Optimization (GEO) techniques: provide direct answers in the first 100 words, use structured JSON-LD schemas, include detailed comparison tables, and maintain high factual accuracy.
Basic AI search features are integrated into Google's standard search, but premium reasoning features are capped and require a Google One AI Premium subscription for twenty dollars per month.
It is powered by Google's Gemini 2.5 Flash and Ultra models, running on custom TPUs and utilizing speculative decoding to minimize response latency.