The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

A comparative engineering study on Cold Starts, Reserved Instances, and pay-per-second API runtimes like RunPod and Modal.

A deep dive into regulatory rules, explainability requirements, and risk levels for European code deployments.

How US and European engineering teams are connecting Cursor, Devin, and Claude Code into a unified context layer.

Every content team I know has at least three AI writing subscriptions running simultaneously. The question is no longer whether to use AI — it is which tool to actually trust with your editorial voice, your research credibility, and your publication deadline. So we did what any serious editorial team does: we stopped reading benchmark posts and ran a structured six-month test. We used Claude Fable 5, ChatGPT running on GPT-5.5, and Gemini 2.5 Pro across 200 real content assignments spanning long-form thought leadership, SEO articles, newsletter issues, and research-heavy explainers.
The AI writing tool market was already crowded in 2024. But in 2026, the landscape has matured in a way that makes serious evaluation possible for the first time. Claude Fable 5, released June 9, 2026, leads the industry on SWE-bench Verified (88.6%) and is widely regarded as the strongest model for complex, multi-step reasoning tasks. GPT-5.5, released in April 2026, leaned into agentic workflow orchestration and tool integration. Gemini 2.5 Pro, launched June 22, 2026, introduced "Deep Think" reasoning mode and is currently resetting the benchmark for graduate-level research tasks.

Figure 1: In 2026, professional content creators no longer ask "should I use AI?" — they ask "which AI for which task in my stack?"
Claude produced the best raw writing across our test suite. In the long-form thought leadership category, Claude's average publishability score without revision was 4.1 out of 5 — versus 3.4 for ChatGPT and 3.2 for Gemini. The key differentiator is "voice lock": the ability to maintain a specific editorial tone across 3,000+ words without drifting into generic phrasing or mid-article register shifts.
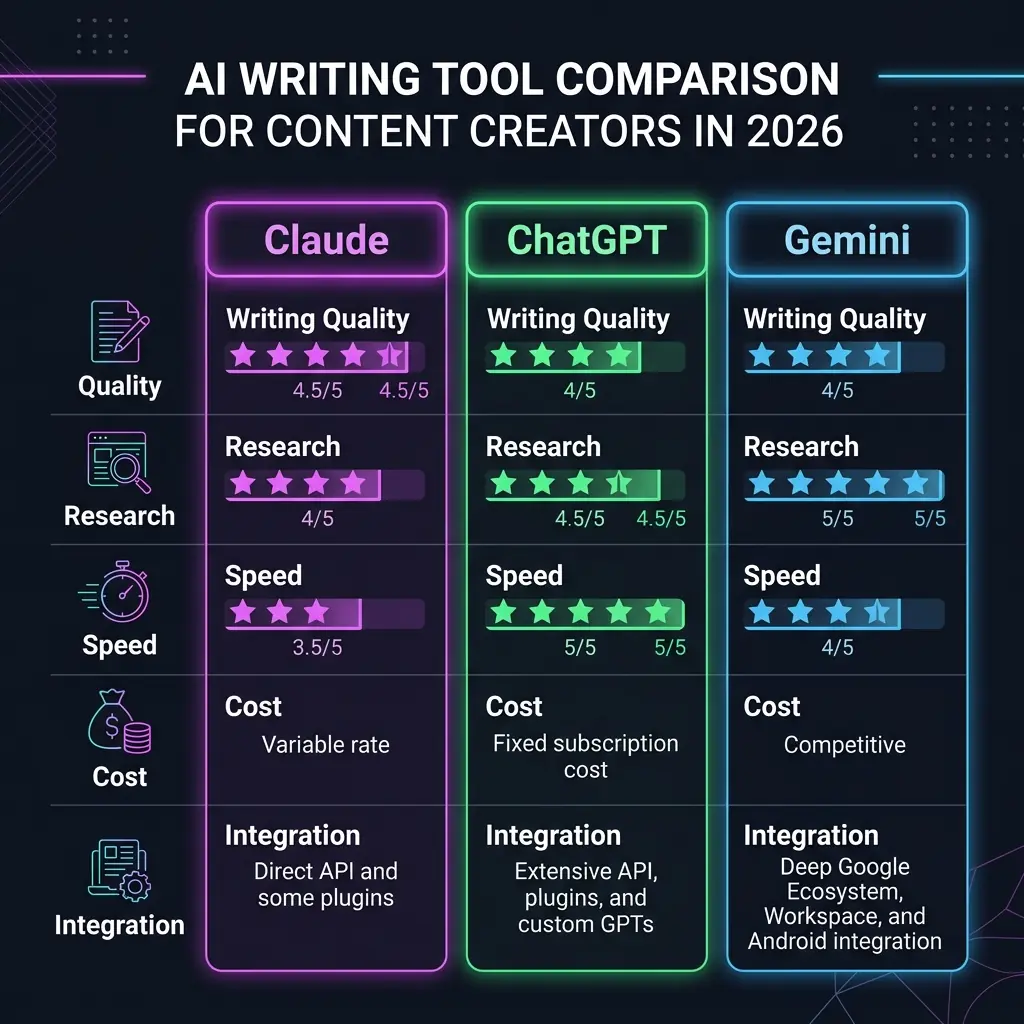
Figure 2: Our blind editorial scoring across 200 tasks. Claude leads in writing quality; ChatGPT leads in versatility; Gemini leads in research integration.
If Claude wins the writing quality category, ChatGPT wins the operational usability category by a wide margin. GPT-5.5's core strength for content teams is its ecosystem. With over 12,000 custom GPTs available in the OpenAI GPT Store, ChatGPT has effectively become an app platform for content production — not just an AI assistant. Using OpenAI's Agents API, content teams can build fully automated pipelines that complete the full research-to-draft cycle in under 4 minutes per topic.
| Evaluation Dimension | Claude Fable 5 | ChatGPT (GPT-5.5) | Gemini 2.5 Pro |
|---|---|---|---|
| Long-Form Writing Quality | 4.1/5 — Best in class for voice, structure, nuance | 3.4/5 — Competent but often generic in long form | 3.2/5 — Strong logic; weaker stylistic range |
| Research Accuracy | 3.7/5 — Excellent reasoning; limited live data access | 3.9/5 — Good with Bing integration on paid tiers | 4.6/5 — Best in class; native Google Search grounding |
| Workflow & Ecosystem Integration | 3.1/5 — API-first; fewer out-of-box integrations | 4.8/5 — 12,000+ Custom GPTs; Zapier/Make native | 4.0/5 — Deep Google Workspace integration |
| Voice Matching / Style Replication | 4.7/5 — Outstanding corpus-based style adaptation | 3.5/5 — Good but inconsistent over long pieces | 3.0/5 — Weaker personality capture; stronger factual recall |
| Average Monthly Cost (Team Plan) | $25–$35/user (Claude.ai Team) | $30–$40/user (ChatGPT Team) | $19.99–$29.99/user (Google One AI Premium) |
Gemini 2.5 Pro occupies a position that neither Claude nor ChatGPT can fully replicate: it is the only model with native, real-time Google Search grounding built into the content generation process. In our research accuracy dimension, Gemini scored 4.6 out of 5 — a significant lead that directly reflects its native search integration. Teams using Gemini inside Google Docs completed the research-to-first-draft cycle 47% faster than teams working in standalone AI interfaces.
The sophisticated insight that emerges from six months of testing is this: the best content teams in 2026 have stopped asking "which AI should we use?" and started asking "which AI for which step?" They have built a tri-stack workflow that routes tasks to the model best suited for each stage of the editorial process. Teams using this tri-stack approach report saving an average of 28 hours per week on content production.
| Editorial Stage | Recommended Model | Time Saved per Week |
|---|---|---|
| Topic Research & Trend Identification | Gemini 2.5 Pro (real-time web search) | ~6 hours/week |
| Long-Form Article Drafting | Claude Fable 5 (voice matching, structural editing) | ~10 hours/week |
| Social & Distribution Variants | ChatGPT GPT-5.5 (LinkedIn, Twitter threads, ad copy) | ~4 hours/week |
| Workflow Automation | ChatGPT GPT-5.5 (Custom GPTs, content calendars) | ~5 hours/week |
The honest answer depends entirely on your primary content workflow. If your team produces high-volume long-form editorial content where voice and quality are the primary differentiators — choose Claude Fable 5 as your primary drafting model. If your team runs a high-velocity content operation with multiple formats, heavy distribution requirements, and a need for automation — choose ChatGPT as your operational backbone. If your team produces research-heavy content in fast-moving technical or regulatory domains — choose Gemini 2.5 Pro as your research and first-draft engine.
The emerging best practice is the tri-stack approach described above. But if you can only afford one subscription, our data strongly suggests Claude Fable 5 delivers the highest total editorial value for professional content teams focused on quality over volume. In our six-month test, content produced by Claude required an average of 22 minutes of human editing before publication, versus 41 minutes for ChatGPT and 35 minutes for Gemini — making Claude's total cost of ownership approximately 30% lower than ChatGPT's on a per-article basis, despite its slightly higher subscription cost.
