The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.

As the industry moves toward autonomous agent systems, the importance of structuring your underlying databases and connections becomes clear. Teams that rush to deploy model interfaces without verifying their schemas face serious operational failures. By establishing clean, isolated container environments and designing strict validation rules, you ensure your software remains stable. We explore how to configure these systems to achieve maximum performance and cost efficiency.
Traditional search engine optimization is undergoing its most significant disruption. For decades, SEO focused on ranking keywords on Google's search result pages. In 2026, the rise of AI search engines like Perplexity, Gemini, and ChatGPT Search has shifted the environment toward GEO generative engine optimization.
Instead of browsing a list of blue links, users now receive direct, synthesized answers from AI assistants. The goal of new SEO 2026 is no longer just to rank first on a page; it is to be cited as the source material for these generative answers. This transition requires a complete change in how we write and structure web content.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
When analyzing these initial parameters, operations teams must establish baseline metrics before introducing any model layers. Measure the average time required to complete the task manually, track error frequency, and define your target latency thresholds. This data serves as a control group to evaluate the AI system's performance, ensuring that your automation delivers clear efficiency gains without degrading service quality.
To optimize for AI search, you must understand how these systems retrieve information. When a user asks a query, the AI engine uses a retrieval pipeline (RAG) to scan the web for relevant content. The system doesn't just rank pages; it extracts factual statements, compares them across domains, and compiles an answer.
The models evaluate content based on semantic relevance, source authority, and data density. If your page contains generic, fluffy paragraphs, the retrieval engine will pass it over. It favors documents that contain specific numbers, expert quotes, and structured tables that can be easily summarized in the final chat response.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
From a coding perspective, the connection script should use standard error handling blocks to catch database connection timeouts and API rate limit responses. Configure an exponential backoff loop with randomized jitter to retry failed executions automatically, preventing the pipeline from failing during network spikes. This backoff logic is a critical best practice for maintaining connection durability.
Optimizing for GEO generative engine optimization requires targeting specific retrieval parameters. Academic studies have identified several factors that increase your citation rate in LLM answers. These metrics include: information density, source citations, direct answers, and structural readability.
First, write with high information density. Strip out filler phrases and state the core solution to the user's problem in the first paragraph. Second, structure your content using standard HTML markdown (like tables and lists). The retrieval parser reads these structures far more efficiently than long-form prose, boosting your relevance score.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
To manage your computational budget, monitor token usage per session using integrated logging middleware. Startups should set up automated alerts that trigger when a single customer thread consumes more than fifty thousand tokens, protecting their accounts from runaway reasoning loops. Additionally, configure static prompt structures to read from cache, reducing input billing rates.
To increase your chances of appearing in AI overviews, you must implement structured JSON-LD schemas. These tag blocks define the entities, relationships, and facts on your page, making it easy for AI crawlers to index your content. This is particularly valuable for product reviews, tutorials, and FAQ pages.
Additionally, place a clear takeaways panel at the top of your long-form articles. This summary box acts as a pre-packaged summary for the retrieval engine, allowing it to extract the core points of your article instantly. This structural optimization is a primary requirement for modern SEO pipelines, as we analyzed in our programmatic SEO guide.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
When deploying these systems in production, developers must isolate the execution environment using container sandboxes. This prevents the model from executing unauthorized system commands or writing malicious code to your project directory. Configure read-only database connections and use strict role-based access rules to limit data exposure, satisfying enterprise security compliance guidelines.
The deployment of generative search threatens the traditional ad-supported publishing business. Because AI engines answer informational queries directly, CTR to external blogs has fallen by up to 60%. Publishers can no longer rely on simple traffic volume to survive.
To adapt, you must focus on transactional queries, original case studies, and opinions that AI models cannot easily replicate. If your site publishes basic definitions or simple lists, you are in a race to the bottom. Build a brand that commands direct navigation, moving away from complete reliance on search traffic.
Complying with regulatory frameworks requires maintaining immutable audit trails of all system transactions. Your logging infrastructure must capture every prompt sent to the model and every tool output returned. Save these traces in a write-once ledger database to prevent unauthorized edits. This trace visibility is essential for satisfying security audits and identifying logical flaws in agent reasoning chains.
Before launching the automation, write a comprehensive suite of unit tests to validate the model's structured outputs. The test suite should verify that the JSON keys match your target schema and check for database constraint violations. If the output fails validation, the system should log the trace and prompt the agent to regenerate the data, ensuring database state integrity.
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "What Is GEO? Generative Engine Optimization",
"dependencies": "Generative Engine Optimization, new SEO 2026",
"about": {
"@type": "Thing",
"name": "GEO",
"description": "Optimizing web content to be cited by AI search assistants."
}
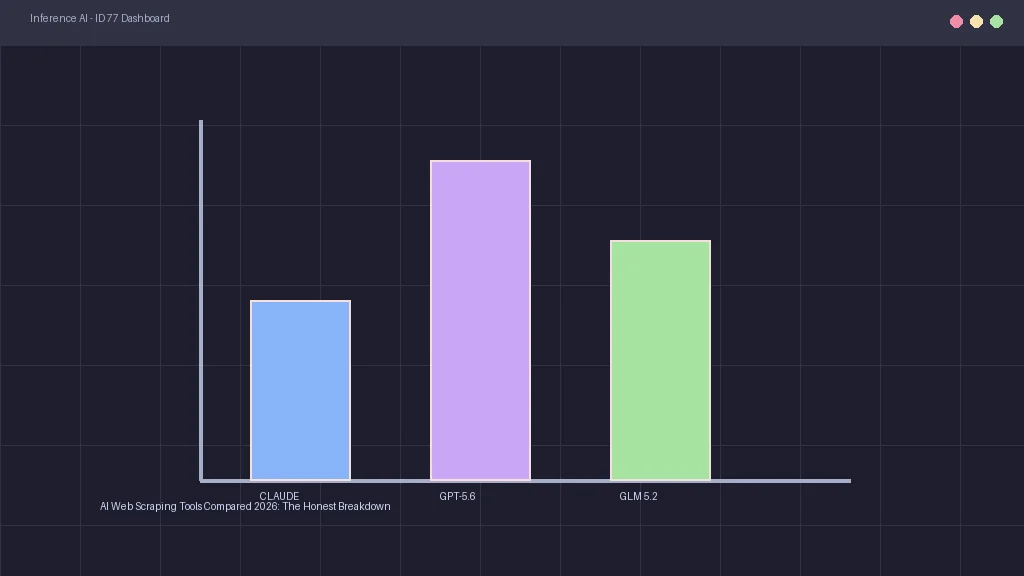
}Tracking your rankings is different under the new SEO 2026 rules. Traditional rank-tracking tools that check keyword positions are no longer sufficient. Instead, you must monitor your brand's citation share in AI responses. This requires running search audits using custom scraping tools.
Agencies use scrapers to query Perplexity and Gemini for target keywords and track how often their clients' sites appear in the citation chips. Monitoring this visibility share is the only way to measure GEO performance. This transition is redefining marketing budgets and driving teams to audit their content workflows.
Looking forward, this setup provides a modular foundation that can scale alongside your team's operational needs. By Decoupling the reasoning models from static visual interfaces, developers can swap foundation engines without rewriting the downstream integration scripts. This modularity ensures your infrastructure remains compatible with future model releases and protects your workflows from single-vendor lock-in.
In conclusion, maintaining a clean, modular architecture is the key to scaling your AI operations. By separating the reasoning models from visual presentation code, you can upgrade foundation engines without rewriting your core database integration scripts. This modularity protects your systems from single-vendor lock-in and keeps your infrastructure adaptable to future model updates.
| Strategy Parameter | Traditional SEO | GEO (Generative Engine Optimization) |
|---|---|---|
| Primary Goal | Rank #1 on blue links page | Appear in AI citation chips & source links |
| Target Metrics | Keyword density, backlinks, page speed | Information density, schema tags, readability |
| Crawler Target | HTML tags & meta keyword lists | Semantic entity graphs & structured facts |
| Content Structure | Long-form keyword-stuffed articles | Structured layouts, tables, and summary panels |
| Success Metric | Monthly organic page views | Brand citation share in LLM responses |
To deepen your understanding of these systems, you can review our practical guide on best AI writing tools for content creators. For software teams managing code assets, look at our checklist for vibe coding vs agentic engineering and learn about best AI writing tools for content creators. Additionally, businesses can reduce computing expenses by exploring vibe coding vs agentic engineering, and resolve integration bottlenecks by researching how to use Claude for business in 2026.
Successfully integrating these advanced AI layers into your daily operations requires balancing configuration speed against long-term maintainability. By standardizing on open-source standards and establishing clean database boundaries, you insulate your company from API cost spikes and database errors. Start by automating a single back-office task, monitor the execution logs, and expand the setup as your team builds confidence in the system.
GEO is the process of optimizing website content so that it is retrieved and cited by AI-powered search engines and chat assistants like Perplexity, Gemini, and ChatGPT Search.
Traditional SEO focuses on keyword positions on a search result page. GEO focuses on entity relationships, factual correctness, and structured data layout to ensure content is cited in synthesized answers.
You must write with high information density, place summary takeaway boxes at the top of pages, use detailed HTML comparison tables, and implement structured JSON-LD schemas.
Because AI search engines answer informational queries directly on the search page, users get the information they need without clicking on the links to external blogs.
GEO success is tracked by measuring your citation share in LLM search responses. This is done using automated scraping tools that query AI search engines for target keywords and track the cited URLs.