The Futures of Work, Decoded.
In-depth editorial coverage of workflow design, automation mechanics, and the systematic shift toward local-first knowledge infrastructure.
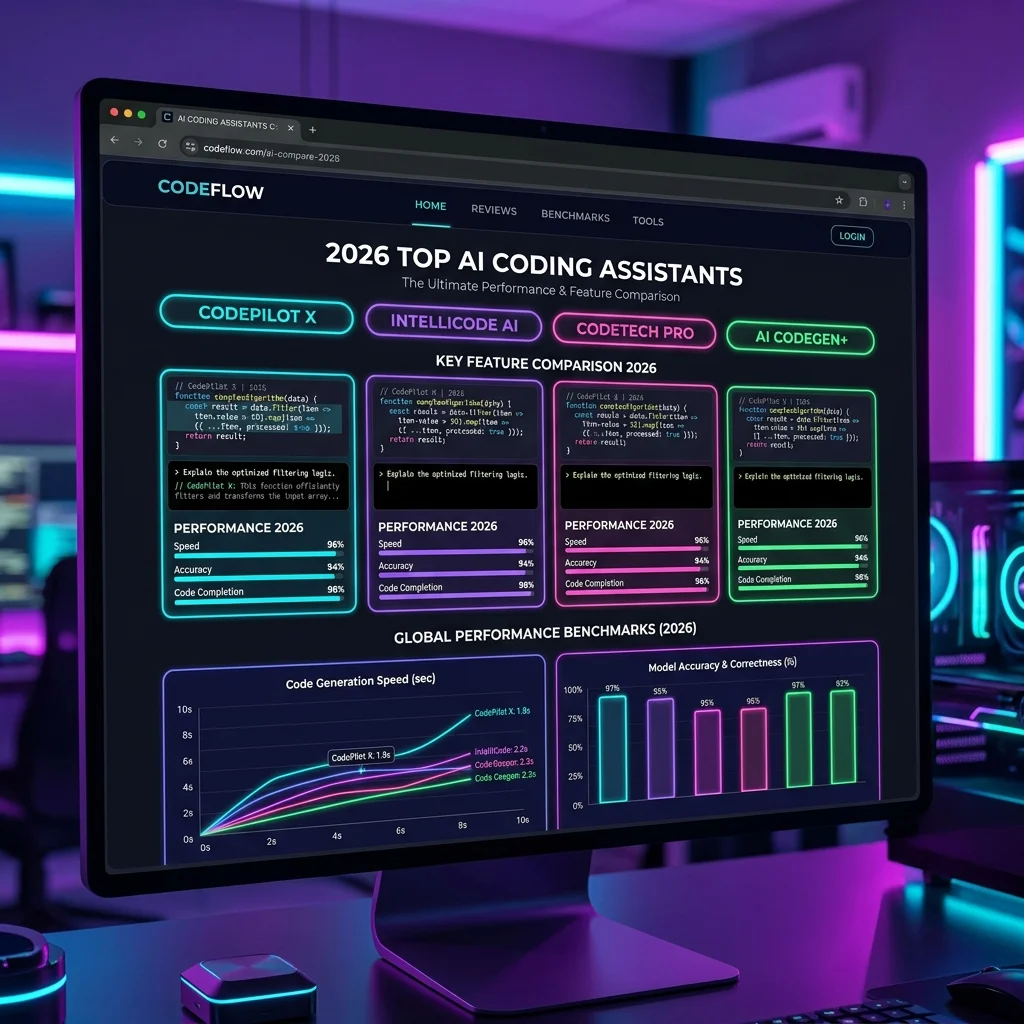
The shift from conversational chatbots to autonomous agents is the defining theme of technology in 2026. Rather than waiting for human turn-by-turn prompts, **autonomous AI agents** can accept a high-level goal, outline their own sub-tasks, execute code, browse the web, write to databases, and self-correct errors until the goal is fully achieved. For organizations seeking to streamline backend operations, automate content pipelines, or scale developer bandwidth, choosing the right agent stack is critical. Here is our hands-on review of the best autonomous AI agents in 2026.
Software engineering is the most mature domain for agentic autonomy, where systems now operate on full repositories rather than individual files:
For custom business logic and multi-agent systems, developers are building tailored workflows using robust agent frameworks:
For data gathering and market intelligence, autonomous information agents can scour the web and compile reports:
The transition to agentic AI workflows represents a fundamental shift in business operations. By choosing the right agentic stack—whether it's terminal coding with Claude Code or structured workflows via LangGraph—you can unlock massive productivity gains while keeping operational token overhead low. Align your team's workflows by reviewing our guide on Agentic AI vs Traditional Automation or study our detailed checklist for Building a Production-Grade AI Agent.
The marketing language around AI agents often obscures how these systems actually function. Understanding the technical mechanics clarifies both their genuine capabilities and their real limitations, enabling you to select agents that match your actual use cases rather than their promotional descriptions.
An AI agent at its core is a language model augmented with three capabilities: tool access (the ability to call external functions, APIs, and services), memory (some form of state persistence between steps), and a planning loop (a mechanism for breaking a goal into steps, executing them sequentially or in parallel, and evaluating progress). Most modern agents implement the ReAct (Reasoning + Acting) loop: the LLM reasons about what to do next, selects a tool action, executes it, observes the result, and reasons about the next step based on the updated state. This loop continues until the agent reaches the goal or encounters a failure that requires human intervention.
The quality of an agent system depends critically on three factors: the reasoning capability of the base LLM (which determines how well the agent plans and recovers from errors), the quality of the tool interfaces (poorly documented or unreliable tools are a primary source of agent failures), and the specificity of the goal specification (agents given vague goals make poor intermediate decisions; agents given specific, well-constrained goals with clear success criteria perform dramatically better). Most agent failures in production can be attributed to one of these three factors rather than to fundamental limitations of the agent architecture itself. For teams building agents, understanding these failure modes is as important as understanding how to build the agent in the first place, as covered in our guide on production AI agent governance.
The AI agent market in 2026 has stratified into distinct categories, each with clear leaders and appropriate use cases. Understanding this stratification helps you select the right agent for your specific workflow rather than evaluating agents by generic capability claims.
Web research agents are the most mature category. Perplexity AI Pro, Exa.ai's research APIs, and the research mode in Claude 3.5 Sonnet all perform well at multi-step web research — gathering information from multiple sources, synthesizing it, and presenting cited summaries. For business intelligence, competitive analysis, and literature review tasks, these agents reliably produce high-quality outputs. Software engineering agents — Claude Code, Devin 2.0, Cursor Agent mode — represent the fastest-advancing category. These agents can autonomously complete 30-40% of well-specified coding tasks without human intervention, and assist with an additional 40-50% through collaborative back-and-forth. Computer use agents (Claude's computer use API, Operator by OpenAI, BrowserBase's agents) can control desktop and browser environments autonomously — filling forms, navigating UIs, extracting information from visual interfaces. These are powerful but brittle, prone to failing when UIs change. Workflow orchestration agents (n8n AI agents, Zapier AI, Make.com AI components) are the most practical for business users — they connect existing SaaS tools through AI-directed decision-making, enabling non-technical users to automate complex cross-application workflows without code.
The selection framework: choose web research agents for information synthesis, coding agents for software development, computer use agents for UI automation, and workflow orchestration agents for business process automation. Mixing categories (using a coding agent for business process automation or vice versa) typically produces poor results. Matching the agent category to the task type is the single most important factor in achieving good agent performance. For teams building agentic workflows, combining the right agent category with the best automation tool for your team is covered in depth in our guide to n8n vs Make vs Zapier for AI workflows.
Deploying an AI agent in a production context — one where it takes real actions with real consequences (sending emails, creating records, executing code, making API calls) — requires a different evaluation methodology than evaluating an agent in a demo environment. Production agent evaluation must assess reliability across the full distribution of inputs the agent will encounter, not just the clean examples in a demo.
The production evaluation framework for AI agents has four components. First, task completion rate: across a sample of 50-100 representative real tasks, what percentage does the agent complete successfully without human intervention? Anything above 70% is production-viable for tasks with low-cost failures; above 90% is required for tasks with high-cost failures (customer-facing communications, financial transactions). Second, failure mode classification: when the agent fails, what type of failure occurs? Planning failures (agent can't determine the right approach), execution failures (agent knows what to do but can't do it reliably), and hallucination failures (agent generates confident but incorrect outputs) each require different remediation approaches. Third, cost-per-task: for API-billed agents, the token cost of completing each task at production volume. Many agents that appear cheap in demos are prohibitively expensive at scale due to multi-turn reasoning loops consuming thousands of tokens per task. Fourth, safety incident rate: how often does the agent take an action that causes unintended negative consequences (sending an email to the wrong recipient, deleting data it should not have accessed)?
Ongoing production monitoring requires logging every agent action with sufficient context to reconstruct why the agent took it. Reviewing a random sample of action logs weekly catches systematic biases or failure patterns before they accumulate into significant incidents. Building an explicit human escalation path — a clear mechanism for the agent to signal that it is uncertain and needs human guidance — dramatically reduces the safety incident rate by ensuring that genuinely ambiguous situations reach a human decision-maker rather than being handled by an uncertain agent. The audit and monitoring infrastructure for production agents directly supports compliance with governance frameworks reviewed in our AI agent observability guide.